- HOME
- マルチエージェント強化学習のシミュレーション適用事例(サンプルプログラムあり)
2022年10月 5日 10:00
シミュレーション適用事例
として、シミュレーションで解決できる様々な事例を紹介しています。
NTTデータ数理システムで開発しているシミュレーションシステム S4 Simulation System 上での実装例もご紹介します。
マルチエージェント強化学習
強化学習では、正しい行動の与えられていない状況で、エージェントが様々な試行を繰り返し、うまくいった/いかなかったという結果を経験しながら、うまくいくための行動(最適な行動)を学習します。
この時、対象となる環境は定常であることが想定されています(状況が変わってしまうと基本的には再度学習し直しが必要になります)。
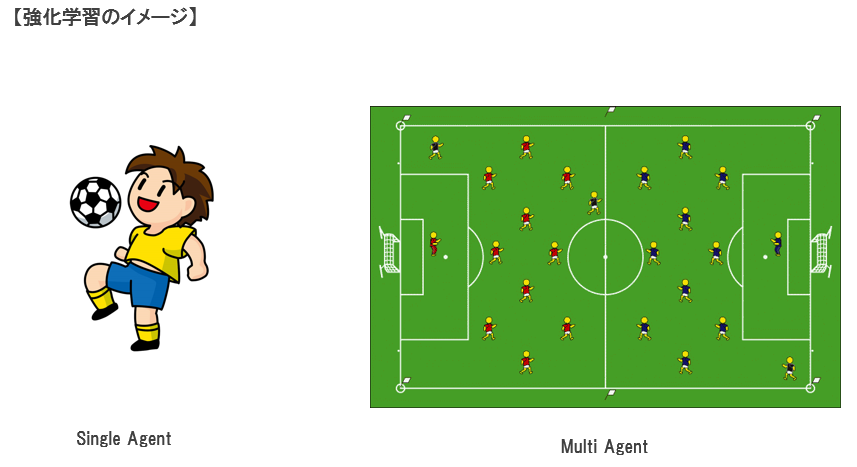
シングルエージェントの強化学習の例として、左図の例では、一人でサッカーの練習をしています。 相手(=環境)はボールで、その取り扱い方(技術)を学習(習得)します。 取り扱い方が上手になったとしても(学習したとしても)、ボールの反応は変わりません(定常です)
一方、マルチエージェントの例として、右図の例はサッカーの試合になります。 敵も味方もエージェントとなります。味方とは協調しながら、敵とは競合しながら得点を狙います。 この場合、あるエージェントにとって、他のエージェント(敵も味方も)は環境の一部となります。 敵の戦術(=環境)に合わせてこちらも戦術(=施策)を学習しますが、敵もこちらの戦術に合わせて、自チームの戦術を変える(学習する)のでこちらから見ると環境が常に変化していることになります。 この様に、他のエージェントも学習するということは、学習とともに環境が変化するという非定常な状況になってしまい学習は難しくなります。 実社会では、環境にたいしてエージェントが一人しかない場合というのはまれで、複数のエージェントが協調/競合しながら活動をしているのが一般的となります。 このような状況における強化学習がマルチエージェント強化学習になります。
S4 Simulation System のエージェントシミュレーション機能と、マルチエージェント強化学習ライブラリ (MARLパッケージの MADDPG) を使えば、マルチエージェント強化学習を実装する事ができます。
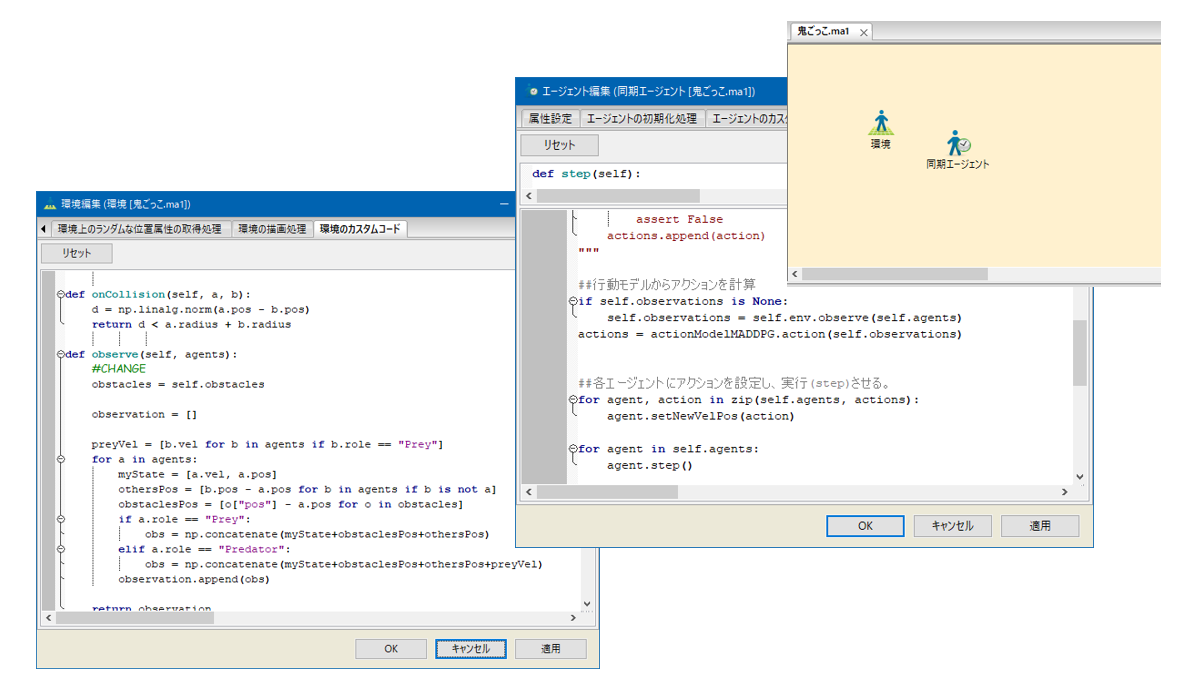
例として、障害物がある状況での鬼ごっこを取り上げます。
逃げるエージェントが1人、追いかけるエージェントが3人います。
追いかける側の観測値は、自分の位置と速度、障害物の相対位置、その他のエージェントの相対的な位置、逃げる側の絶対速度としています。 逃げる側の観測値は、自分の位置と速度、障害物の相対位置、その他のエージェントの相対的な位置としています。 エージェントの行動のパラメータは、水平、垂直方向の加速度であり、報酬として、追いかける側が逃げるエージェントを捕まえると報酬をもらい、逃げるエージェントは同時にペナルティを課されるとします。
【マルチエージェント強化学習とシングルエージェントの強化学習との比較】
マルチエージェント強化学習の場合、先回りして、敵を挟み込んで捕まえる協調動作を学習している事がわかりますが、シングルエージェントの強化学習の場合、そもそも学習がうまくいっておらず、不思議な動作をするエージェントもいる事がわかります。
このように、エージェント同士が協調する方が最適化できる場合には、マルチエージェント強化学習は有効です。例えば、自動車同士が強調して、交通渋滞を減らしたり、工場の中で効率よく AGV やロボットを制御すること等が、応用例として考えられます。
参考文献
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
サンプルプログラム
S4 Simulation System のマルチエージェント強化学習のサンプルプログラム (Ver6.1以降) を提供しています。 ファイルサイズが大きいため、大変お手数ですが お問い合わせフォーム より「S4 Simulation System マルチエージェント強化学習サンプルプログラム」の旨をご記入いただいた上、お問い合わせください。
その他サンプルプログラム一式をダウンロードするにはこちら。
おわりに
シミュレーションについて
他にもシミュレーションで解決できる課題の例をシミュレーション適用事例としてご紹介しています。
そもそもシミュレーションとは?シミュレーションってどうやるの?等の疑問をお持ちの方に向けて、具体例も交えて紹介・解説する【1から分かるシミュレーション読本】を無料公開しています。 よろしければ併せてご覧ください。
S4 Simulation System について
「S4 Simulation System」は、複雑なモデルGUI上で表現しを誰でも簡単にシミュレーションを行なえるソフトウェアです。本記事でも「S4 Simulation System」でのシミュレーション実装例をご紹介しました。
30日間の無償トライアルでシミュレーションモデルをご自身で動かしていただくことも可能です。ご興味をお持ちの方は下記のフォームからお問い合わせください。
また、「S4 Simulation System」のご紹介とハンズオンでのシミュレーション体験を行うオンラインウェビナーを毎月無料で開催しております。ご興味をお持ちの方はぜひご参加ください。












