テクニカルサンプルプロジェクト
データ分析のステップアップのために
本ページではNTTデータ数理システムのデータ分析ソリューションの基本的な使い方から典型的な分析の利用例、 さらに一歩進んだ分析手法まで、その手順を表現したプロジェクトファイルとその解説を紹介しています。
プロジェクトファイルの使い方
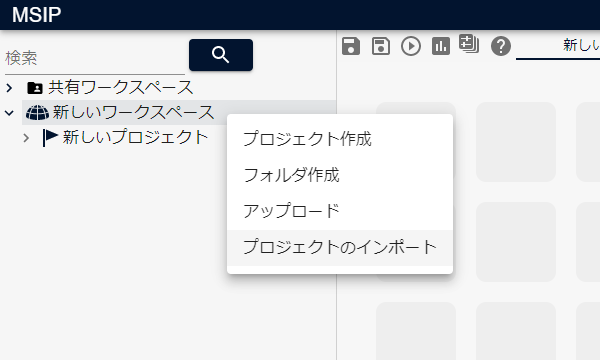
プロジェクトダウンロードのリンクより、 データ分析ソリューションのプロジェクトファイル (.msiprj ファイル)がダウンロードできます。 データ分析ソリューションのワークスペースブラウザ上 で ワークスペース を右クリックし、 プロジェクトのインポートから .msiprjファイル を指定し読み込んでご使用ください。
テクニカルサンプルプロジェクトのご利用について
テクニカルサンプルプロジェクトおよび解説ドキュメントは、(株)NTTデータ数理システム(以下「弊社」)が
開発・販売する分析プラットフォームについての情報提供として弊社が作成をおこなったものです。
弊社による事前の許可なしに、解説ドキュメントの再配布や引用の範囲を超える複製といった行為、
およびテクニカルサンプルプロジェクトのリバースエンジニアリングを禁じます。
テクニカルサンプルプロジェクトならびに解説ドキュメントのご利用に際して、
ご利用者様および第三者に損害が発生しても、弊社は責任を負わないものとします。
テクニカルサンプルプロジェクトファイルは、その中に同梱されているデータを利用し、
解説ドキュメント内で解説している設定可能なパラメータで、最新バージョンの製品上で動作させた場合についてのみ、
弊社にて動作の検証をおこなっております。
これを超えるような状況における動作は保証いたしません。
ご要望はこちらまで
Alkano テクニカルサンプルプロジェクト
ここではデータ分析プラットフォームAlkanoで利用できる、 テクニカルサンプルプロジェクトのプロジェクトファイル、 および解説ドキュメントをダウンロードしていただけます。
- Alkano分析アイコンチートシート
- Alkano・BayoLinks可視化機能チートシート
- 時系列クラスタリング分析
- テキストデータの可視化・類似検索
- ベイズ最適化による実験パラメータの推薦・最適化
- 異常検知モデルに対するドリフト検知
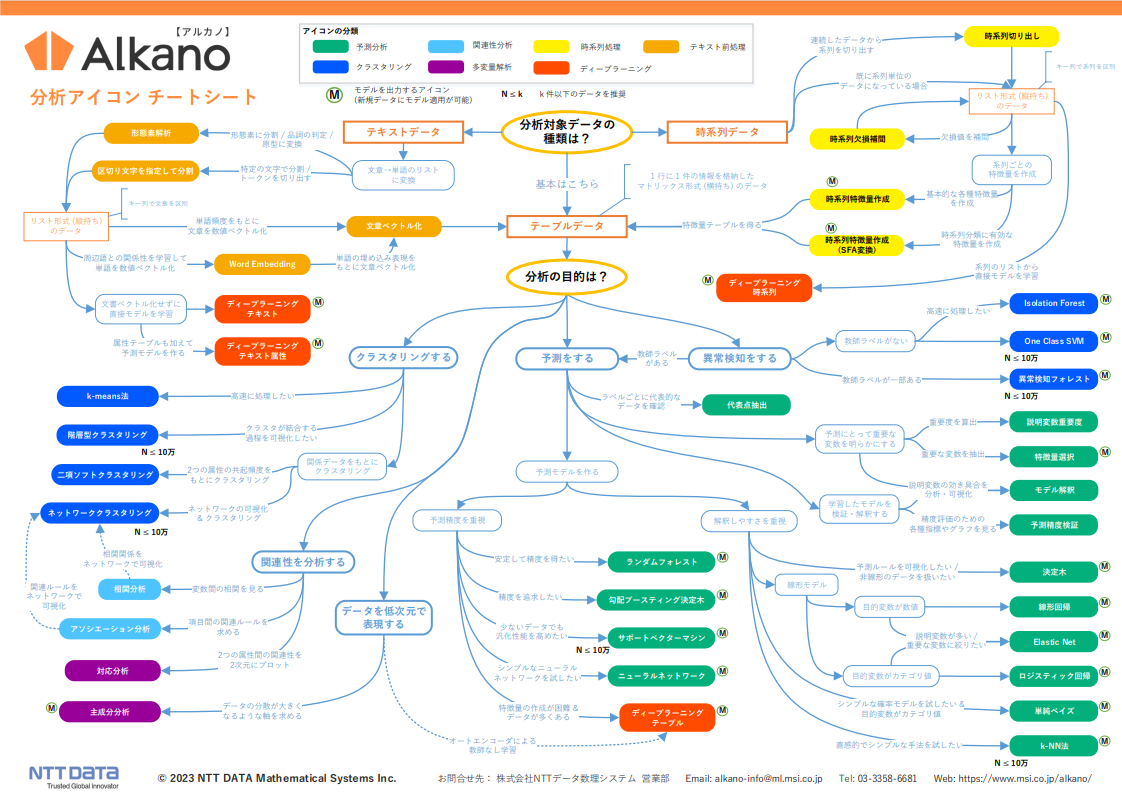
![]() Alkano分析アイコンチートシート
Alkano分析アイコンチートシート
こんな方にお勧めします。
- Alkanoの分析機能を用途から逆引きしたい方
Alkano 分析アイコンチートシート は、あなたの 分析目的 や 分析対象データの種類 に応じて、適切な Alkano の分析機能を選択するためのフローチャートです。
Alkano の多彩な分析機能の全体像をつかみ、使い分けを知るためのガイドとして、Alkano を使い始めた方からヘビーユーザーの方まで幅広くご活用いただけます。

![]() Alkano・BayoLinkS可視化機能チートシート
Alkano・BayoLinkS可視化機能チートシート
こんな方にお勧めします。
- お手持ちのデータをどのように可視化できるのか知りたい方
Alkano は多彩な可視化の機能を設けています。このチートシートでは、お手持ちのデータから、可視化したい情報のタイプや観点に応じてどういったグラフが作成できるかを示しています。
ぜひともデータの把握や分析結果の確認に、このチートシートをご活用ください。
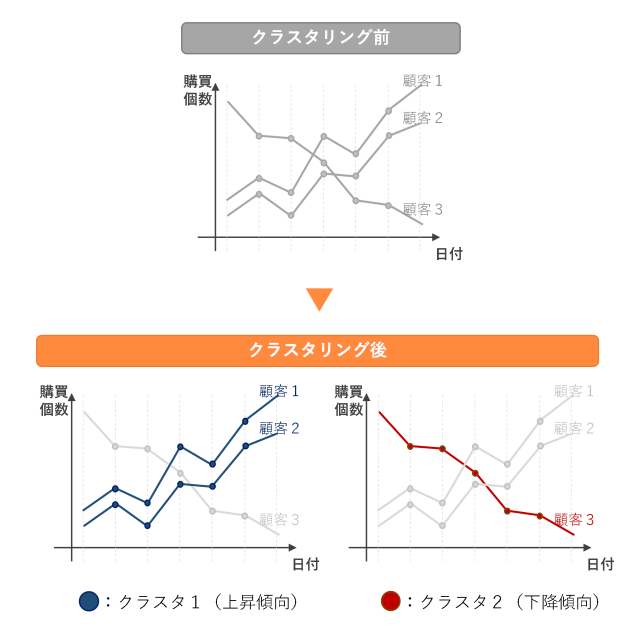
![]() 時系列クラスタリング分析
時系列クラスタリング分析
キーワード
時系列データ、探索的分析、教師なし学習、パネルデータ
こんな方にお勧めします。
- たくさんの時系列の間に潜む共通のパターンを見出し、データの理解に役立てたい方
- 時系列データを機械的に分類・整理するための時系列クラスタリング手法に興味がある方
ビジネスでは、小売店の購買データや
製造設備のセンサーデータなど、様々な時系列データが日々蓄積されています。
しかし、たくさんの時系列データを単に眺めるだけでは、有用な知見を得るのは困難です。
本プロジェクトでは、時系列クラスタリングを用いることで、複数の時系列を系列間にある共通パターンからグループ化する方法をご紹介します。
さらに、時系列データのグループ化と「AutoModeling 将来予測」アイコンによる分析を組み合わせることで、
抽出したパターンの将来動向を予測する例も紹介します。
例えば、小売店の「顧客購買データ」を対象にした本プロジェクトの分析では、
顧客の購買行動に基づくグループ化や、行動パターンごとの商品購入予測を通じて、
有効なマーケティング施策を検討することが可能です。
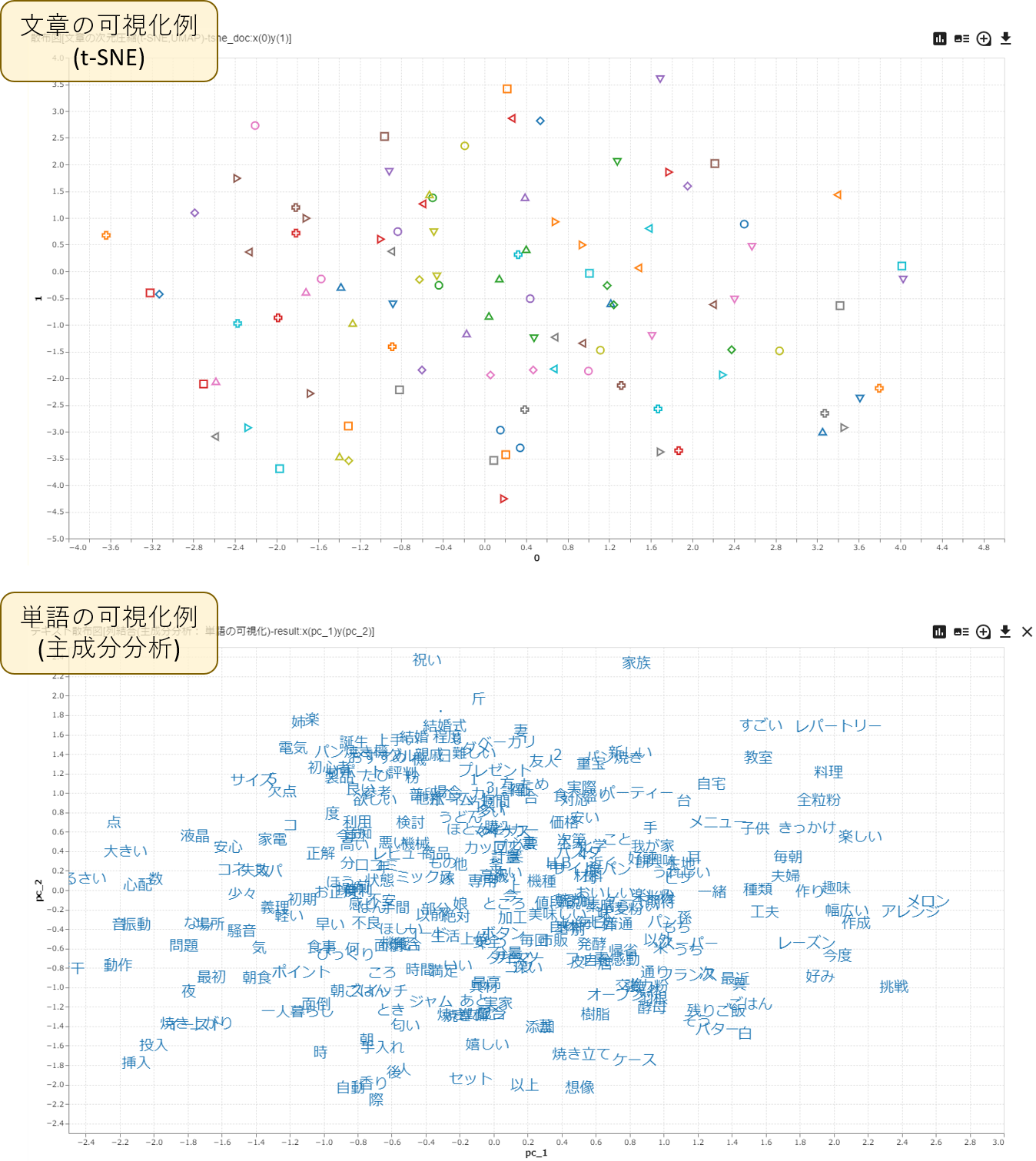
![]() テキストデータの可視化・類似検索
テキストデータの可視化・類似検索
キーワード
テキストデータ分析、次元圧縮、テキストデータ可視化、クラスタリング、類似検索、t-SNE、UMAP
こんな方にお勧めします。
- 膨大なテキストデータを効率的に分析したい方
- 類似検索(特定データと似たデータの抽出)をしたい方
膨大なテキストデータの分析を行う際にテキスト全てに目を通すことは、実務上・時間上難しい場合があります。 そのため、特定のデータやそれに似たデータだけを抽出し、効率的に分析を行うことが必要になってきます。 このプロジェクトでは、次元圧縮を用いたテキストデータの可視化・クラスタリングを行うことで似た傾向のデータをグループ分けし、 新規データが既存データ群のどれに近いかの類似検索をベクトルの距離計算で行っています。 テキストの次元圧縮については、古典的に利用されてきた主成分分析の他、t-SNEやUMAPなどの近年注目を集めている手法を利用しています。
![]() ベイズ最適化による実験パラメータの推薦・最適化
ベイズ最適化による実験パラメータの推薦・最適化
キーワード
マテリアルズインフォマティクス、材料開発、ベイズ最適化
こんな方にお勧めします。
- マテリアルズインフォマティクスを活用して、最適な素材の配合比や生成条件を求めたい方
- 製造条件 と 製品の特性値 との関連性を分析し、最適な製造条件を明らかにしたい方
- 実験データが少ない場合でも ベイズ最適化 を活用して効率的に最適条件を探りたい方
材料開発など一般に試作品を作成するのに大きなコストがかかるケースにおいて、マテリアルズインフォマティクスが注目されています。
素材の配合比などの製造条件と製品の特性の関連を実験データから明らかにし、最適な素材の配合比や生成条件を見つけるという試みです。
このプロジェクトでは、過去の実験データ、すなわち配合比・生成条件などの製造条件に対応する実験パラメータ(説明変数)と特性値(目的変数)の値から
ベイズ最適化によって特性値が大きくなる(または小さくなる)ような実験パラメータを探索、試すべき製造条件を推薦します。
また、実験データから学習した予測モデルを利用した、製造条件の最適化を行います。

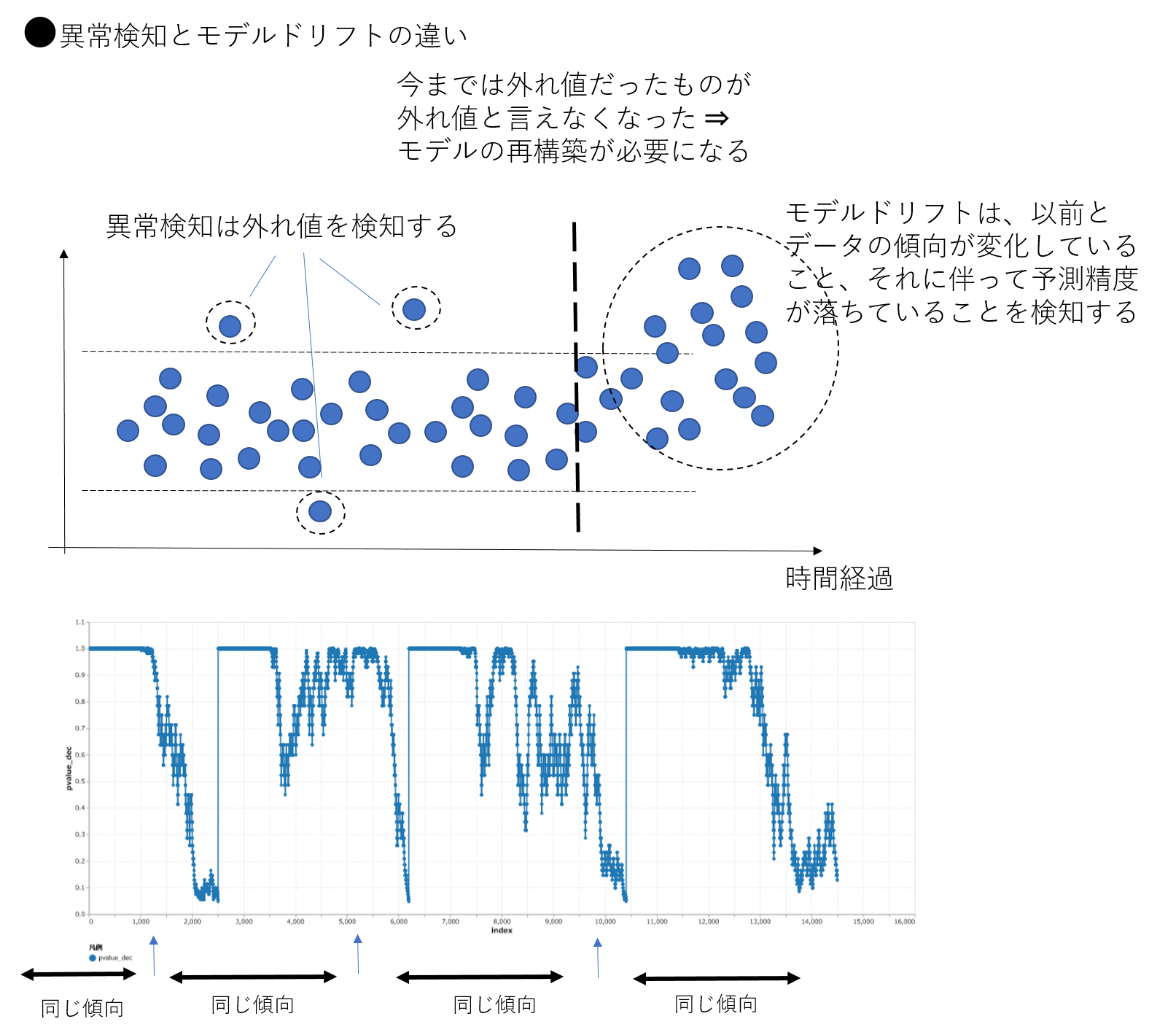

![]() 異常検知モデルに対するドリフト検知
異常検知モデルに対するドリフト検知
キーワード
機械学習、モデル精度、異常検知、コンセプトドリフト、モデルドリフト、ドリフト検知、再学習
こんな方にお勧めします。
- 運用中の機械学習モデル・異常検知モデルに対し、精度低下を監視し再学習を行うタイミングを検知したい方
- 日々流入するデータについて、傾向の変化を数値的に確認したい方
作成した機械学習モデルを使用していくと、最初のうちは精度よい予測が行えていたのに、徐々に予測の精度が落ちて来たかも、ということはありませんか。
このような場合、データの変化(コンセプトドリフト)やそれに伴うモデル精度の劣化(モデルドリフト)を適切に検知し、新しいデータで再学習を行うことが一つの有効な方法とされています。
このプロジェクトでは、再学習の起点を知るためのドリフト検知手法を紹介いたします。
具体的には、入力となる特徴量、予測対象、予測結果の分布に対して
現在データが学習当時と同じ分布から生成されたものかを調べる
ことによって、精度変化を検知し予測モデルを監視する方法を紹介いたします。
BayoLinkS テクニカルサンプルプロジェクト
ここではBayoLinkSの テクニカルサンプルプロジェクトのプロジェクトファイル、 および 解説ドキュメントをダウンロードしていただけます。
Alkano・BayoLinkS可視化機能チートシート
こんな方にお勧めします。
- お手持ちのデータをどのように可視化できるのか知りたい方
Alkano、BayoLinkS は多彩な可視化の機能を設けています。
このチートシートでは、お手持ちのデータから、可視化したい情報のタイプや観点に応じてどういったグラフが作成できるかを示しています。
ぜひともデータの把握や分析結果の確認に、このチートシートをご活用ください。
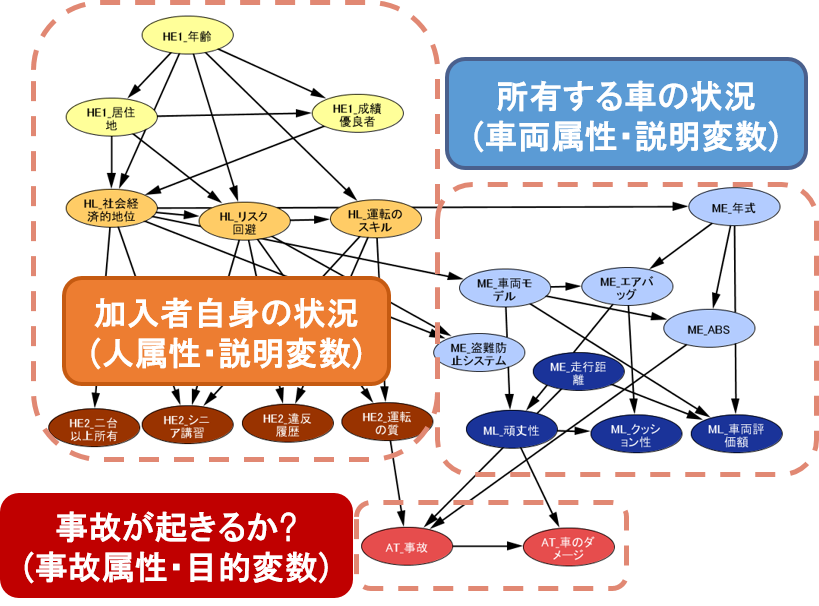
自動車保険データを用いた事故の要因分析
キーワード
ベイジアンネットワーク、推論、要因分析
こんな方にお勧めします。
- カテゴリカルデータを用いた要因分析を効率的に行いたい方
- BayolinkS に搭載している各種機能の利用方法を知りたい方
多変数かつ多カテゴリのデータを用いて、ある事象の要因を探るとき、次のような問題を抱えることが多いです。
- 組み合わせの数が膨大なため、要因の調査に莫大な時間を要してしまう。
- 各変数間の関連性や因果構造が把握しづらい。
本プロジェクトでは BayolinkS を用いて、効率的に因果構造を把握し、要因分析を行います。
TextExtension テクニカルサンプルプロジェクト
ここではTextExtension(Alkano/BayoLinkS 向けテキスト機能拡張パック)と Alkano(データ分析プラットフォーム)を連携することで利用できる、 テクニカルサンプルプロジェクトのプロジェクトファイル、 および解説ドキュメントをダウンロードしていただけます。
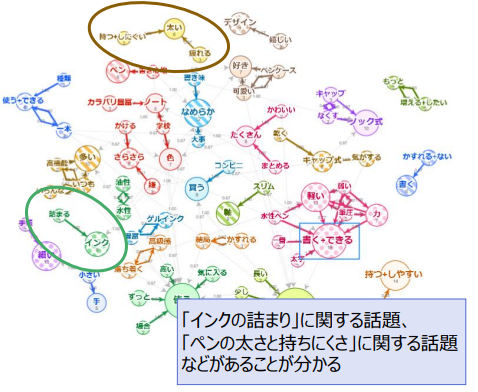
テキストの話題分析 ~共起ルールの抽出~
キーワード
テキストデータ分析、アソシエーション分析、ネットワーククラスタリング、概要把握
こんな方にお勧めします。
- テキストデータから話題を抽出したい方
テキストデータの分析を行う際に、どんな単語が出てきているかということだけでなく、どんな話題が語られているかを把握したいということがあります。
このプロジェクトでは 同時に出現する(共起する)単語同士を抽出する「アソシエーション分析」と、ネットワークを構成して可視化できる「ネットワーククラスタリング」機能を組み合わせて、単語のかたまり(クラスタ)を表示し、話題を把握します。
共起関係は係り受け関係よりも広い関係の単語を抽出できます。また、SNSなど助詞が省略されがちな短い文章でも単語間の関係を抽出できるため、幅広いテキストデータに適用可能な分析です。
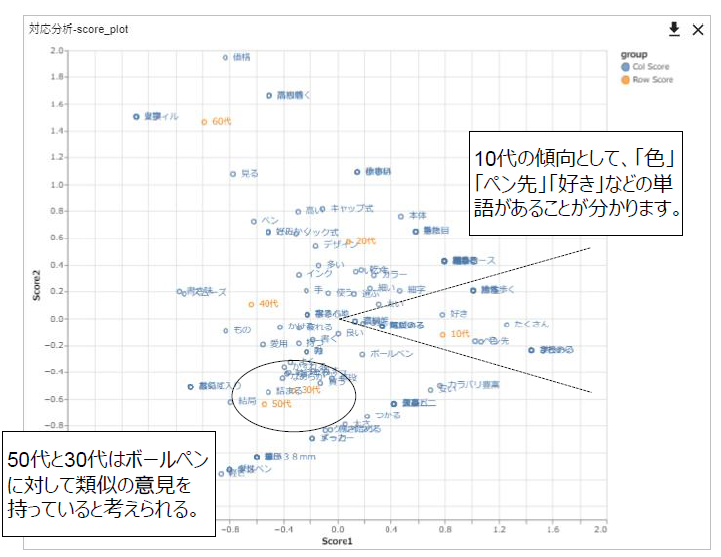
テキストの話題分析 ~対応分析~
キーワード
テキストデータ分析、対応分析、ポジショニングマップ、概要把握
こんな方にお勧めします。
- テキストデータに含まれる単語を介して、属性情報の傾向や話題を把握したい方
テキストデータの分析において、テキストデータに付随する属性情報との関係を見ることも重要です。
このプロジェクトでは、対応分析を用いて、単語と属性の情報を合わせて次元圧縮し2次元平面上に可視化することで、話題や属性値の傾向を把握するための分析を行っています。
対応分析は、要素の関係の近さ遠さを2次元平面上の距離で把握することが可能なため、ポジショニングマップとしても有効です。特にテキストデータに利用する場合、テキスト中のことばと属性の関係を2
次元空間上に分布させることにより、ことばを介した属性の分布を見ることができます。
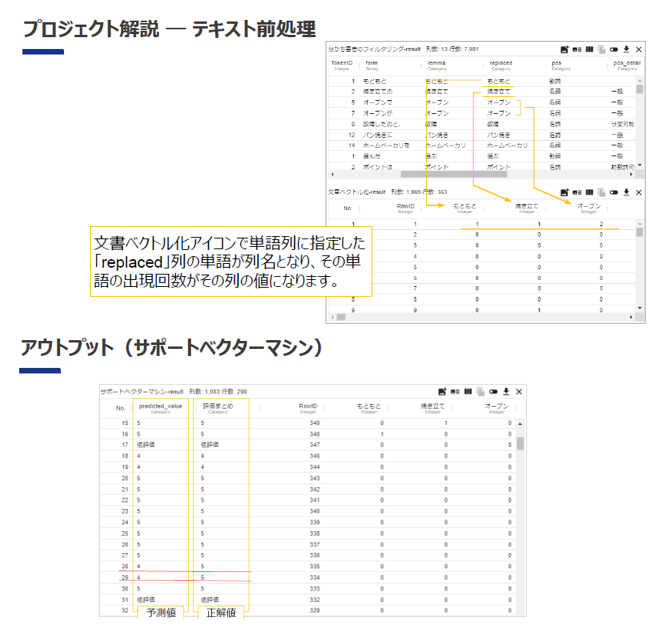
テキストの分類分析 ~サポートベクターマシン~
キーワード
テキストデータ分析、予測モデル、機械学習、モデル精度、サポートベクターマシン
こんな方にお勧めします。
- テキストデータや属性データを利用して、予測モデルを作成したい方
- テキストデータを利用した機械学習を行いたい方
このプロジェクトでは、テキストデータを利用して、機械学習の有名な一手法であるサポートベクターマシンで分類・予測モデルを作成する一連の流れを紹介します。
この流れは、テキストデータを利用した機械学習の一般的なフローとなりますので、これを応用することで様々な機械学習手法をテキストデータでも扱うことができます。
また、付随する属性データも機械学習で利用し、分析することができます。
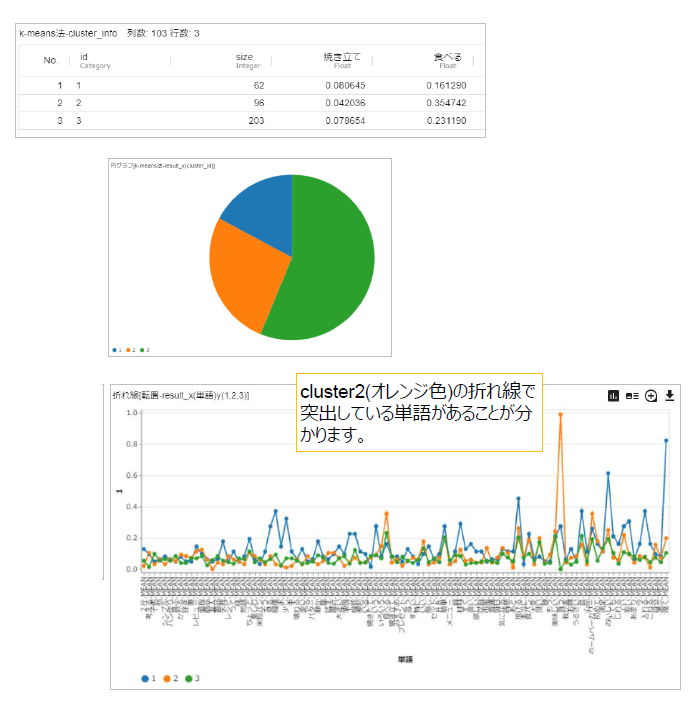
テキストのクラスタリング
~k-means・二項ソフトクラスタリング~
キーワード
テキストデータ分析、クラスタリング、k-means、二項ソフトクラスタリング
こんな方にお勧めします。
- テキストデータや属性データを利用してテキストをグループ分け、話題を抽出したい方
- テキストデータを利用した機械学習を行いたい方
このプロジェクトでは、いわゆる「教師なし学習」であるクラスタリングという手法を用いてテキストデータをクラスタリング(=グループ分け)する一連の流れを紹介します。
ここでは、クラスタリングとして有名な、k-means法と二項ソフトクラスタリングの2手法をご説明します。
この流れは、テキストデータを利用した機械学習の一般的なフローであり、これを応用することで様々な機械学習手法をテキストデータでも扱うことができます。