
Deep Learner 新バージョン 1.1 をリリースいたしました
Deep Learner 1.1 の新機能をご紹介いたします。
(画像をクリックすると拡大します。)
新機能一覧
Word Embedding アイコンを新設しました
テキストデータを分析する際の、新たな次元圧縮の手法を提供いたします。 既存機能である Deep Learner アイコンでは、設定項目 "データ" を「テキスト」、 "用途"を「次元圧縮」とすることでテキストデータの 1 件 1 件を固定の次元のベクトルとして表現した次元圧縮表現を得ることができますが、 Deep Learner Word Embedding アイコンでは、テキストの構成要素である「単語」そのもののベクトル表現を得ることができます。

Deep Learner Word Embedding アイコンでは、
- Continuous Bag of Words (CBoW)
- Skip-Gram
上記のモデルを用いて計算を行いうことができます。その結果、単語の出現する文脈が類似しているような単語同士は ベクトル表現同士の類似度も高くなるように学習が行われます。この結果を用いて、単語同士の類似度を、ベクトル同士の距離を計算することで評価でき、 またデータマイニングツール Visual Mining Studio (※) や Deep Learner アイコンで単語そのものを対象とした 分類モデルの構築や可視化を行うなどの応用が可能です。
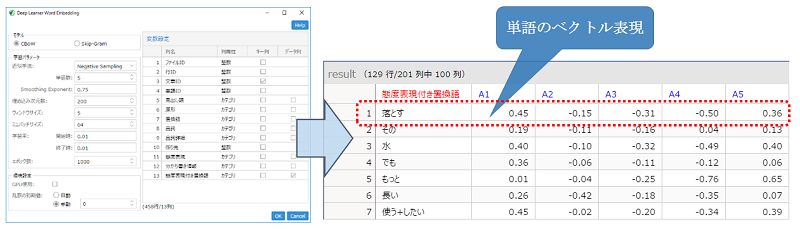
テキストデータは、テキストマイニングツール Text Mining Studio の分かち書き処理を用いて
単語への分割を事前に行っておくことが必要です (※)。また、本アイコンは、テキストデータへの適用を前提としている機能ですが、
可変長のアイテムの系列からなる、カテゴリ (文字列) 系列データ であれば
適用が可能です。例えば、個人毎の商品購入履歴といったデータに適用させた場合は、購入アイテムを同時に買われやすいアイテムの類似性に応じて
ベクトル化するといった効果が得られますので、POS データ分析の際にもご活用ください。
(※) 別途ライセンスが必要です。
学習済みモデル情報の出力が可能になりました
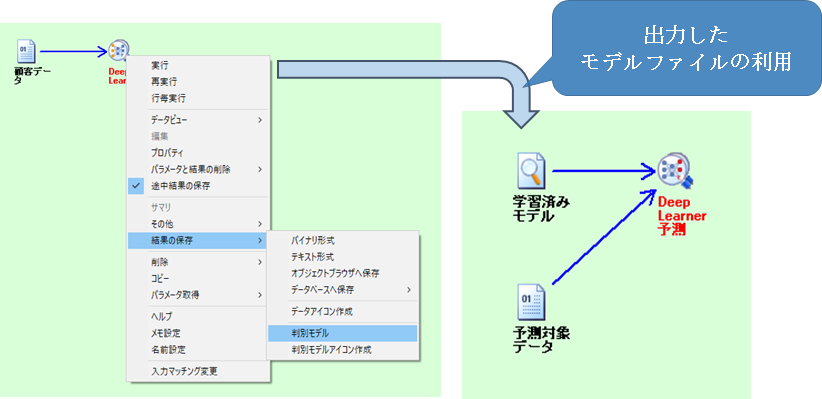
Deep Learner アイコンで、学習済みのモデルの情報を拡張子 .vModel のファイルとして出力できるようになりました。
.vModel ファイルは、そのままプロジェクトボード上に貼り付けて、学習済みの Deep Learner アイコンと同様
Deep Learner 予測アイコンに接続して予測を行うことができます。
これにより、学習したモデルの情報のみを配布したい、学習を行った環境とは別の環境で予測のみを行いたい、といった場合に対応可能です。
データの重み付けが可能になりました
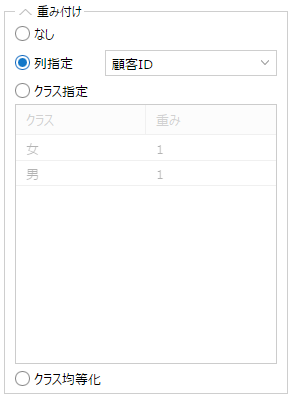
Deep Learner アイコンで、データに重みをつけて学習させることが可能になりました。
予測モデル構築時、目的変数がカテゴリ1列の場合に利用可能です。
正常か異常かを判定させたいが異常データの方が少ないなど、予測対象カテゴリ毎のデータ数に著しい偏りがある場合、
特にデータの少ないカテゴリに重みをつけて学習における影響度を増大させるといった利用方法が可能です。
また「クラス均等化」のオプションを用いると、学習に対する寄与を等しくするよう、カテゴリ毎のデータ数から重み値を自動的に計算します。
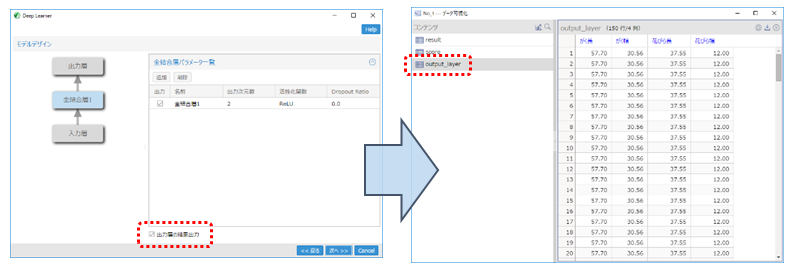
次元圧縮時のデータ復元が可能になりました
Deep Learner アイコンで、"用途"「次元圧縮」の利用時に、AutoEncoder で復元されたデータそのものを出力し確認できるようになりました。 設定項目 "データ" が「テーブル」の場合に利用が可能です。
その他の変更点
Deep Learner アイコン Model Optimizer 機能で探索される値のうち、 実数値を持つもの (Dropout Ratio) の有効数字が小数点以下 4桁 に固定されました。