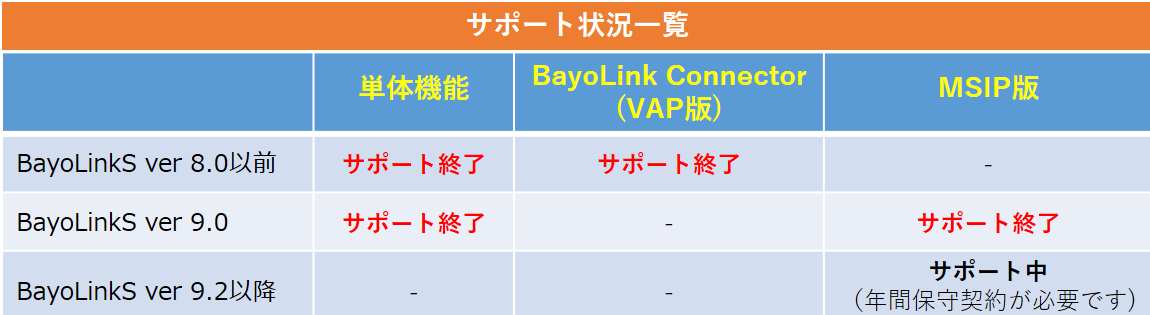
BayoLinkS単体機能(ver 9.0)は技術サポートを終了しました。
BayoLinkS の仕様・価格など
C:\MSIP
続いて、元のバージョンのBayoLinkS をインストールします。
(※ 新しいバージョンで作成したプロジェクトやシナリオは古いバージョンでの動作を保証しておりません)
分析プラットフォームがVAPからMSIPへ移行したためです。 ただし、BayoLinkS単体機能で作成したベイジアンネットモデルは、モデルファイルをMSIP(ver.1.8以降)へアップロードした後、ネットワーク編集アイコンから引き続きご利用いただくことができます。
単体機能からver.9以降のBayoLinkSで分析を行うための移行ガイドを用意しています。MSIP移行ガイド.pdfをダウンロードしてご参照ください。
インストール・ライセンス登録・起動に関するトラブル(ver.8.0 以降)
- ・ver.9.0以降からのバージョンアップ
- ・ver.8.0からのバージョンアップ
- ・ver.7.4 以前からのバージョンアップ
■契約情報の受信
・どの製品か
・インストールしていただける製品のバージョン
・ご利用の期間情報
・ライセンス数の情報
■PC固有の情報の送信
(PC のハードウェア情報などから算出するもので、算出方法については非公開とさせていただきます)
詳しくは使用許諾書をご参照ください。
お客様が製品で利用されたデータなどは送信されませんのでご安心ください。
MSIP上での操作について
離散化の区間は等間隔や等数、χ二乗等で計算することができます。
グルーピングは等間隔、等数、群内二乗和によって自動的に分割されます。また任意の区間で分割することもできます。
詳細については、MSIPのユーザーリファレンス「3.8.11. 離散化」、「3.8.12. グルーピング」をご参照ください。
なお、アンケートの回答などの場合は、「列属性変更」ノードで整数値をそのままカテゴリ化することができます。
(1) 文字のエンコードが BOM付きのUTF-8
(2) 使用禁止文字が含まれるデータ
使用禁止文字は以下が該当します。
【半角文字 】
「=」(イコール)、「,」(カンマ)、「:」(コロン)
【全角文字】
「―」、「~」、「?∥」、「-」、「¢」、「£」、「¬」
【環境依存文字】
「①」、「?」、「⊿」など
「分析実行中にエラーが発生しました:スコア計算対象のノードがデータ列内にありません. 変数名=XXXX」
【循環回避のエラー例】
「分析実行中にエラーが発生しました:循環回避に失敗しました:該当するノードがデータ列内にありません. 変数名=YYYY」
ノード名の冒頭か末端に全角のブランク、または2つ以上の半角のブランクが存在する場合、プログラム内部で自動的に削除されます。この処理により入力データとの不一致が生じるため、上記のようなエラーが発生します。前もってブランクを除去する等、入力データのノード名を変更または修正してください。
一方、"全探索" は指定された探索空間を全探索しますので、その解は取り得る全ての状態の中で評価基準値が最も良い厳密解となります。しかしながらノードの数が多い場合には時間的な問題、メモリの問題により実質的に探索不可能となります。
GreedySearch は近似解法ですので、一般的にその解は厳密解とは異なります。しかしながら 全探索 に比べ、時間とメモリのコストの削減が期待できます。このような場合を含め何らかの原因で厳密解が求めることが不可能な場合に、有効な探索アルゴリズムです。
- 既存の学習データにフィットしたモデルを作成したい
- 将来得られる未知のデータにフィットした(予測精度の高い)モデルが作成したい
仮に前者の目的であれば、相関や尤度などの統計量や人の目から見て自然かなどの基準によりモデルを作成していくことになるかと思います。また、後者の目的であれば、AIC や MDL
などのペナルティ値を含む情報量基準を用いたり、交差検証により予測精度を評価したりしていくことになるかと思います。
このように情報量基準をデータや目的によって容易に使い分けることを可能にしている面は
BayoLinkS の一つの機能であります。
親ノードの数を減らす、または各ノードの 状態数を減らすことで学習が可能となる場合があります。
またノードの数を減らしたくない場合は、全親ノードについてリンクを逆転させ子ノードとするのも有効です。
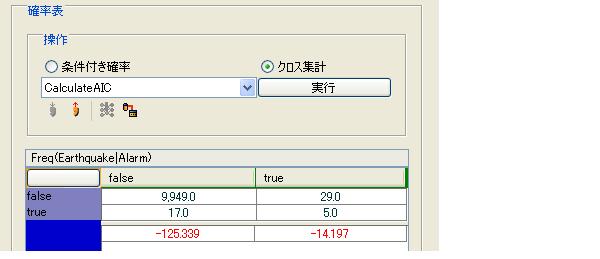
集計結果と推論の結果が異なる理由として主に以下があります。
1.構造学習の正規化手法に「MAP」を選択している場合
「MAP」を選択している場合にはクロス表の各セル 1 を足して正規化しています。この場合は「ML」を選択すれば一致します。
2.クロス表において全ての値が 0 のカラムがある場合
クロス表のカウントが全て 0 となるカラムがある場合確率計算の結果はデータの集計と大きく異なるケースがあります。このようなカラムの確率分布は一様分布が与えられます。この分布はデータに基づいたものではありませんので、データ集計との乖離の原因となります。
3.推論アルゴリズムによる誤差
BayoLinkS の推論アルゴリズムは近似解法ですので、グラフ構造によって誤差がでることがあります。この場合は、推論アルゴリズムを MSSM に変更し、samplecount の値を増やしていくと一致するようになります。
なお、「ネットワーク編集」アイコンでは推論アルゴリズムを変更することはできません(「loopyBP」に固定されています)。
旧バージョン(VAP版および単体機能)について
インストール・ライセンス登録・起動に関するトラブル
詳しくは下記の「Visual Analytics Platform インストールガイド」をご参照ください。
C:\Program Files (x86)\Mathematical Systems Inc\Visual Analytics Platform\インストールガイド_VAP.pdf
「2.2.1. NET Framework 3.5.1 の有効化」
インターネットに接続していただき、Windows のスタート→[MSI Solutions]→[BayoLinkS ライセンスの登録・更新] を実行してください。 もし解決されなかった場合、インターネットに接続していただき、Windows のスタート→[MSI Solutions]→[BayoLinkS のシリアル ID の変更]を実行してください。表示された画面のスクリーンショットを『 製品サポート 』までお送りください。
モデルの自動構築について
変数の数
変数の数が増えるとモデルの探索空間が大きくなるため、探索に時間がかかるようになります。
探索アルゴリズム
・全探索
指定された探索空間の全てのモデルを探索します。計算のオーダーは N * 2^N (2 の N 乗の N 倍、N は変数の数) となります
・Greedy Search
指定された探索空間内のモデルを小さなモデルから順に探 索し、良いモデルが見つからなくなるまで探索します。一般に全探索よりも計算量は小さくなります。
変数の状態数
状態数が大きな変数は、生成される CPT のサイズが大きくなります。
変数の親の数
状態数が小さくても親の数が多くなると、生成される CPT のサイズが大きくなります。
メモリの上限を上げる
BayoLinkS 単体機能の実行で使用可能なメモリは当初512MB(ver 5.0.1以降は1024MB)に設定されています。初期設定のまま大規模データで構造学習を行うとメモリ不足が発生することがあります。
・関連項目
使用メモリの上限を変更したいのですが
最大親数を指定する
モデル構築ウィザードの2ページ目で[最大親数]という項目があります。ここをチェックすると各ノードの親候補を指定した数で制限します。例えば、「3」と指定してモデル探索すると、各ノードの親は最大でも三つまでというモデルが構築されます。
参考までに、以下は構造学習を行った場合のベンチマークです。
| ノード数 | レコード数 | 処理時間(秒) |
|---|---|---|
| 20 | 100万 | 45 |
| 80 | 20万 | 60 |
・Windows 10 (x64) CPU: Intel Core i7-7700T CPU 6420 @2.90GHz 2.90GHz
・実装メモリ (RAM): 32GB
・BayoLinkS ver. 7.4
[ERROR] 学習データの読み込みでエラーが発生しました:Comparison method violates its general contract!
これはデータに含まれる数値(またはテキスト値) のパターンや順序などにより、まれに発生するエラーです。
BayoLinkS の設定ファイルを変更することで上記のエラーが回避できます。
1.以下のファイルをデスクトップなどにコピーします。
C:\Program Files (x86)\BAYONET\bnstart.bat
2.コピーしたファイルを開き、13行目を次のように書き換えます。
set XMX=-Xmx1024m -Djava.util.Arrays.useLegacyMergeSort=true
(※) 起動メモリを指定する"set XMX=Xmx1024m" の後に "-Djava.util~" を追加しています。
3.ファイルを保存して閉じます。そのまま元の場所に上書きコピーします。
4.BayoLinkS 単体機能を再起動します。
使用禁止文字
学習データに使用禁止文字が使われていないかご確認ください。使用禁止文字については操作マニュアルを参照してください。
学習データのフォーマット
学習データのフォーマットが不正でないか、以下についてご確認ください。
・各レコードのデータとヘッダーのカラムが完全に対応しているか
・データの最終行の後にリターンのみの行や不正な値が入っていないか

(※)離散化できるのは値の型が「数値型」の 場合です(「数値型」は値が数値のみのカラムが該当します)。 離散化の区間は、K-means法や等区間法で自動計算できます。また任意の区間を指定することもできます。
離散化をしない場合、数値をそのまま状態値とみなします。
離散化についての詳細は 操作マニュアル$6.3.4をご参照ください。
原因の1つとして数値データの離散化が考えられます。
離散化は数個のカラムで行われる分は問題ないのですが、数十個になるとモデル構築時の負荷は非常に大きくなります。このような負荷を抑えるためには次のような方法があります。
- 学習データのカラム数やレコード数を少なくする。
- あらかじめ、数値データをカテゴリ化してテキストで置き換えておく。例えば0から9までを"S1"、10から19までを"S2"などに置き換える。
情報量規準と呼ばれる ML(最大対数尤度), AIC, MDL については 結果として得られるモデルのリンク数に次のような傾向があります。
ML > AIC > MDL
ML はリンクの本数が多く検証では精度が良いという結果となりますが、パラメータ数が多くデータに過剰にフィットしているとも考えられます。未知のデータの予測などに対しては、よりシンプルなモデルが得られるAICやMDLを使う方が 一般的には良いとされています。
以下を行うと、メモリの消費量をおさえ学習が可能となる場合があります。
- 各ノードで状態値の数をできるだけ少なくする (最大で5個くらいに絞る)
- 構造学習の学習アルゴリズムで "欲張り法(Greedy Search)" を使う
- モデルの親子関係の設定で、必須親または親候補を制限する
推論について
・関連項目
使用メモリの上限を変更したいのですが
(1) ノード名や状態値に不正な文字コードが含まれる。 (2) モデルにサイズが非常に大きい条件付確率分布表(CPT)を持つノードがある。
(1)につきましては、ノード名と状態値の名前で使用できない文字は以下の通りです。
\ = “ : | (いずれも半角文字)
(2)につきましては、BayoLinkSの画面左のパネルに表示されますCPTにおいて、サイズが非常に大きいものがないかどうかご確認ください。
なお、CPTが大きくなる要因としては以下が挙げられます。
・親ノードを多数もつノードが存在する。
・ノードのカテゴリ(状態)の多いものを複数組み合わせて親ノードとしている。
上記に該当するノードがありましたら、親ノードを減らす、 状態を減らす等の方法でCPTのサイズを小さくしていただき、 再度ご実行ください。
その他の操作について
・関連項目
使用メモリの上限を変更したいのですが
2.メモリを 1024MB に設定する場合の例
-Xmx1024m
(注意)
変更できる値の上限値はOSやPCの環境等によって異なります。
CTTは、CPTタブ内の[クロス集計]を選択することにより確認できます。
(列数の上限はExcel 2003の場合256個、2007及び2010の場合は16384個です。)
シートに記述する項目の列数は、以下の式で計算できます。
説明変数の個数 + 目的変数の個数 + 全目的変数の状態の和 + 2
(式最後の"2列"は、入力値と出力値の境界と、エラーメッセージの出力に使用します。)
上の式の値が、Excelの列数の上限を超えないように、説明変数や目的変数の数を調整します。 または、一度に指定する目的変数を減らして、複数回に分けて推論を行います。

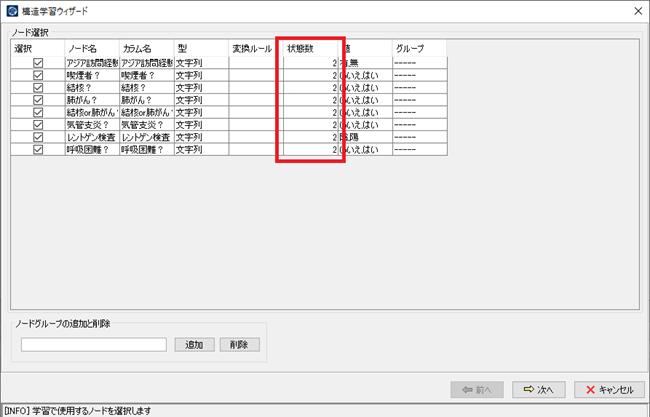
学習データで 列の値が
1種類しかない場合に発生するエラーです
(例えば、ある列の値が全て「AAA」になっている場合)
列の値の種類数については、構造学習のウィザードの「状態数」で確認できます。
BayoLinkS では入力データは文字列型(カテゴリ)を想定しています。数値列が含まれていても学習自体は可能ですが、欠損値は正しく扱われません。
学習データ、検証データについては数値列を離散化してカテゴリに変換するか、ファイル入力時に文字列型に指定してインポートを行ってください。
1.Visual Analytics
Platform(VAP)のメニュー→「製品(P)」→「製品の選択(S)」を押下してください。
2.「製品の選択」画面において、「製品名」のBayoLink
Connectorの左横の「選択」に「×」印が入っているかどうかご確認ください。
もし2.で「×」印が入っていない場合、クリックして「×」印を入れていただいた後、「適用」、「OK」ボタンを押下してください。
2.上部のメニューから「ヘルプ」→「プロパティ」を起動してください。
3.左側の一覧から「構造学習」を選択し、右側のパネルを確認してください。
4.「マルチスレッド数を自動設定する]のチェックを外し、「学習アルゴリズムで使用するスレッド数」に任意のスレッド数を指定してください
(注) 実際にはPCの過剰負荷を避けるため、指定したスレッド数 の7割程度が学習に利用されます。