データベースにデータを書き出す
Pythonアイコン上でODBCを利用してデータベースを参照・更新する方法について紹介します。
3.1. データベース書き出しのための準備
MSIPのPythonアイコン上でODBCを利用するためには、MSIPでODBCを扱える外部ライブラリを利用する必要があります。この「データベース接続ガイド」では、外部ライブラリとしてpyodbcを利用します。pyodbcの詳細にについてはpyodbcのwiki(2023/09/01現在)を参照ください[外部のWebサイトに移動します]。
MSIPで外部ライブラリを利用できるようにする方法の詳細については、「MSIPドキュメント」の「3.10.1. Python アイコン」内の「外部ライブラリの利用方法」を参照ください。この「外部ライブラリの利用方法」に沿ってpyodbcを利用する手順の概要を説明します。この説明では、MSIPが「C:\MSIP」にインストールされているものとします。
- 管理者権限でコマンドプロンプトを起動し、インストール前の環境のバックアップを適当なフォルダ(この例では「C:\temp\requirements.txt」)に保存します
- この例では
C:\MSIP\python\Scripts\python -m pip freeze > C:\temp\requirements.txtと入力し、実行します
- この例では
C:\Windows\System32>C:\MSIP\python\Scripts\python -m pip freeze > C:\temp\requirements.txt C:\Windows\System32>
- MSIPにpyodbcをインストールします
- この例では
C:\MSIP\python\Scripts\python -m pip install pyodbcと入力し、実行します - pyodbcの最新版(この例では4.0.39)がインストールされます
- この例では
C:\Windows\System32>C:\MSIP\python\Scripts\python -m pip install pyodbc
Collecting pyodbc
Downloading pyodbc-4.0.39-cp310-cp310-win_amd64.whl (69 kB)
---------------------------------------- 69.7/69.7 kB 761.9 kB/s eta 0:00:00
Installing collected packages: pyodbc
Successfully installed pyodbc-4.0.39
[notice] A new release of pip is available: 22.0.4 -> 23.2
[notice] To update, run: D:\MSIP\python\Scripts\python.exe -m pip install --upgrade pip
C:\Windows\System32>
3.2. データベースを操作する
まず、準備としてPythonアイコン上で外部ライブラリpyodbcを利用する方法について説明します。 そして、Pythonアイコン上でのpyodbcの大まかな利用方法を理解いただくために、データベースからデータを読み込む方法について、例も交えて説明します。その後、データベース内のデータを更新したり、データを追加する方法を説明します。
- 準備
- データの読み込み
- データの更新
- データの追加
説明では、MSIPの共有ワークスペース内のサンプルデータ「顧客データ.dft」の内容に相当するテーブルデータを参照します。
なお、Pythonアイコン上でデータベースからデータを読み込む処理は、2.5. DataFrameのデータベースAPIを利用してODBC接続するで説明したように、pyodbcを利用しなくても可能です。MSIP上でデータベースからデータを読み込む処理に限れば、DataFrameのデータベースAPIを利用したほうが容易に処理できます。
pyodbcの詳細にについてはpyodbcのwiki(2023/09/01現在)を参照ください[外部のWebサイトに移動します]。
以下の説明では、MSIPのPythonアイコンを利用します。Pythonアイコンの利用方法の詳細については、「MSIPドキュメント」の「3.10.1. Python アイコン」を参照ください。
また、接続に利用するODBCのデータソースは、この「データベース接続ガイド」の2.3.1. MariaDBで作成方法を説明した「mariadb_odbc_driver_test」を利用します。
3.2.1. pyodbcを利用できるようにする
Pythonコードでpyodbcを利用するため、次のコードを追加します。
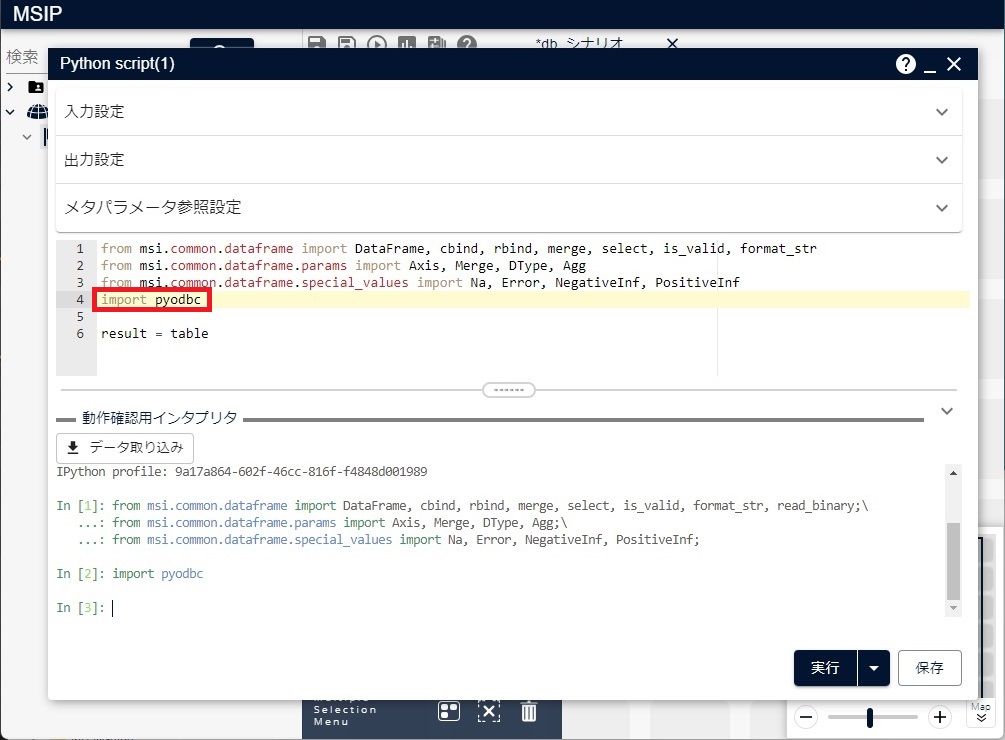
import pyodbc
Pythonアイコンを実行する前にpyodbcが利用できることを確認するには、「動作確認用インタプリタ」で、このPythonコードを実行します。エラーが発生せずに、次の図のように正常に実行できれば利用できます。
3.2.2. データベースからデータを読み込む
ODBCのデータソースを利用して、データベースからデータを読み込む方法を説明します。 この例では、テーブル名を要求するSQL「SHOW TABLES」を実行し、その結果を得ます。
import pyodbc
# データソースを指定してDMBSに接続し、コネクションを作成します
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
# コネクションからカーソルを作成します
cur = conn.cursor()
# カーソルを利用してSQLを実行します
cur.execute('SHOW TABLES')
# 実行したSQLの結果を取得します
rows = cur.fetchall()
# 作成したカーソルを削除します
cur.close()
# 作成したコネクションを削除します
conn.close()
このPythonコードを「動作確認用インタプリタ」で実行すると、次の図のような実行結果を得ることができます。
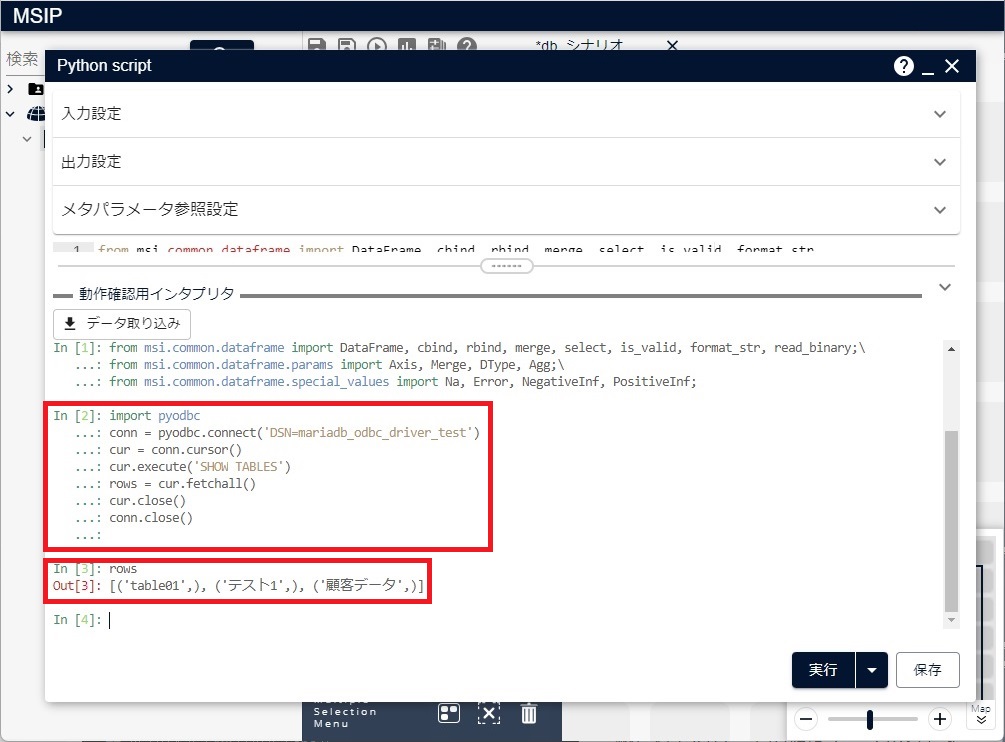
実行結果はリストで、要素はレコードデータです。各レコードデータはタプルであり、要素は各カラムの値です。この例では結果として3レコードのリストを取得しています。各レコードは1つのカラムが格納されており、その値はテーブル名です。
MariaDBのクライアントプログラムで、同じSQLを実行してテーブル名を取得すると、rowsに格納されているものと同じテーブル名が取得できます。
MariaDB [db01]> SHOW TABLES; +-----------------+ | Tables_in_db01 | +-----------------+ | table01 | | テスト1 | | 顧客データ | +-----------------+ 3 rows in set (0.001 sec)
3.2.3. データベースから読み込んだデータからPythonアイコンの出力を作成する
前述した方法でデータベースから読み込んだデータを基に、Pythonアイコンの出力となるDataFrameを作成する方法を説明します。 Pythonアイコンの入力設定のtableは不要なので削除します。 この説明では、データベース内のテーブル「顧客データ」を利用します。
最終的に、データベースから読み込んだデータをPythonアイコンの出力として作成する一連のコードを提示しますが、その前に、コード内の各処理ごとの動作を動作確認用インタプリタで確認します。
最初に、SQL「DESC 顧客データ」を実行して、カラムデータを得ます。
import pyodbc
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
cur = conn.cursor()
cur.execute("DESC 顧客データ")
col_descs = cur.fetchall()
SQL内のDESCは、対象テーブルの定義情報を出力します。
MariaDB [db01]> DESC 顧客データ; +--------------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------------+-------------+------+-----+---------+-------+ | 顧客ID | int(11) | YES | | NULL | | | 年齢 | int(11) | YES | | NULL | | | 性別 | varchar(10) | YES | | NULL | | | 職業 | varchar(10) | YES | | NULL | | | 月収 | int(11) | YES | | NULL | | | 学歴 | varchar(10) | YES | | NULL | | | クレーム回数 | int(11) | YES | | NULL | | | 利用時間 | int(11) | YES | | NULL | | | 収益 | int(11) | YES | | NULL | | +--------------------+-------------+------+-----+---------+-------+ 9 rows in set (0.014 sec)
「動作確認用インタプリタ」でこのPythonコードを実行すると、次の図のような実行結果を得ることができます。
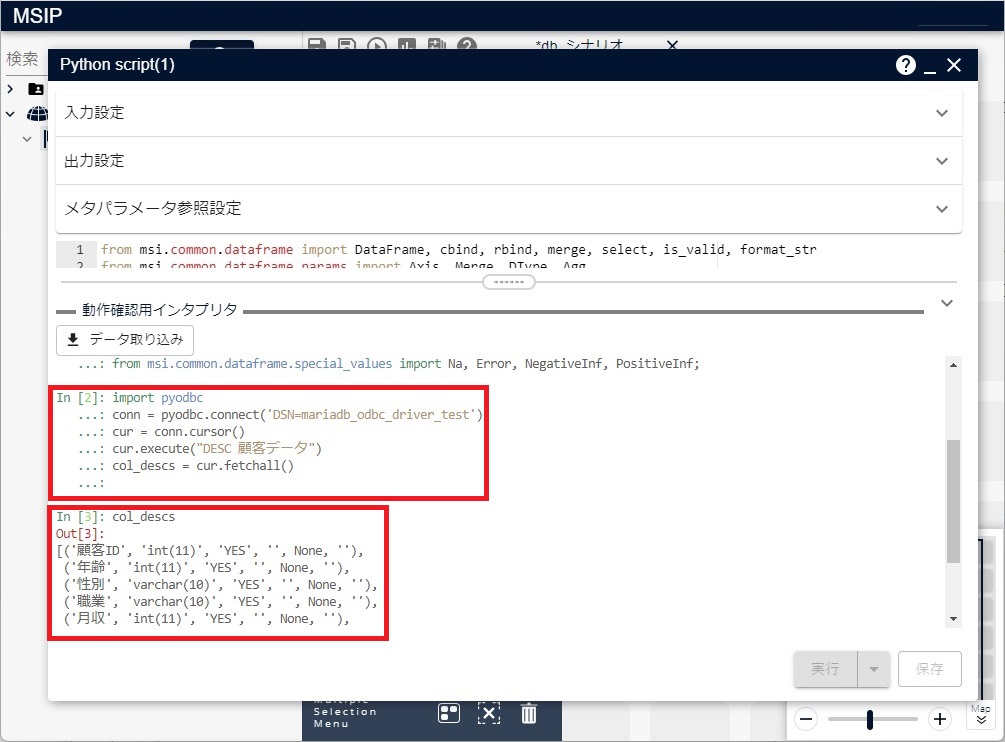
結果リストの各要素は各カラムのデータです。カラムデータの先頭はカラム名です。結果リストから、カラム名のリストを作成します。
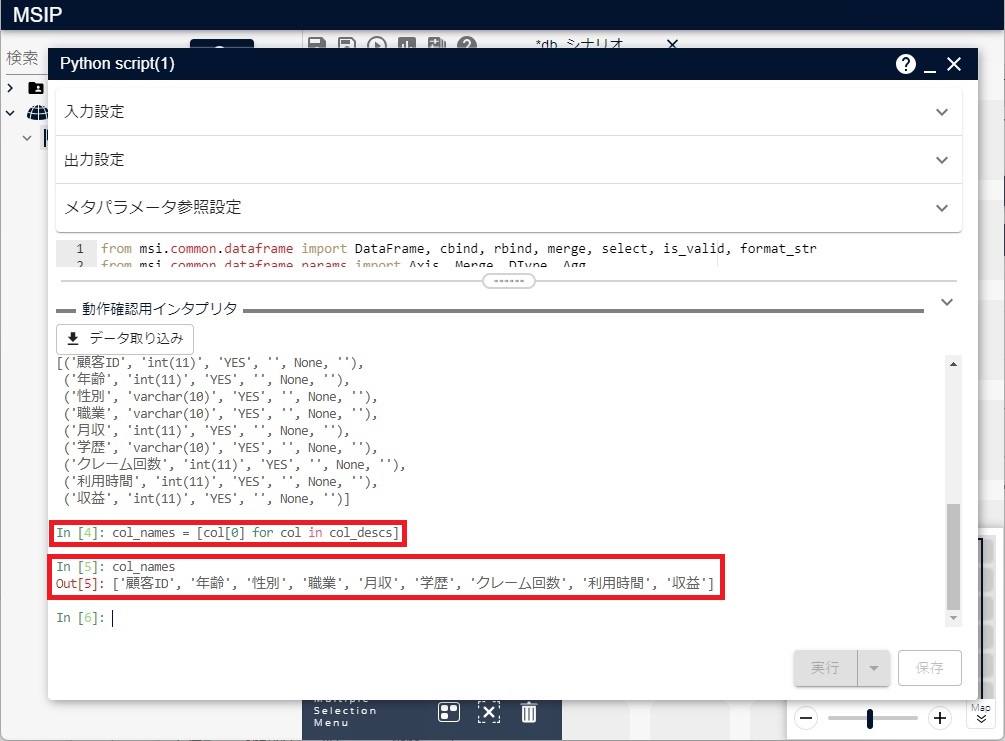
col_names = [col[0] for col in col_descs]
次の図のように、9つのカラム名からなるリストが作成されます。
次に、同じカーソルを利用して、テーブル「顧客データ」のデータを得ます。
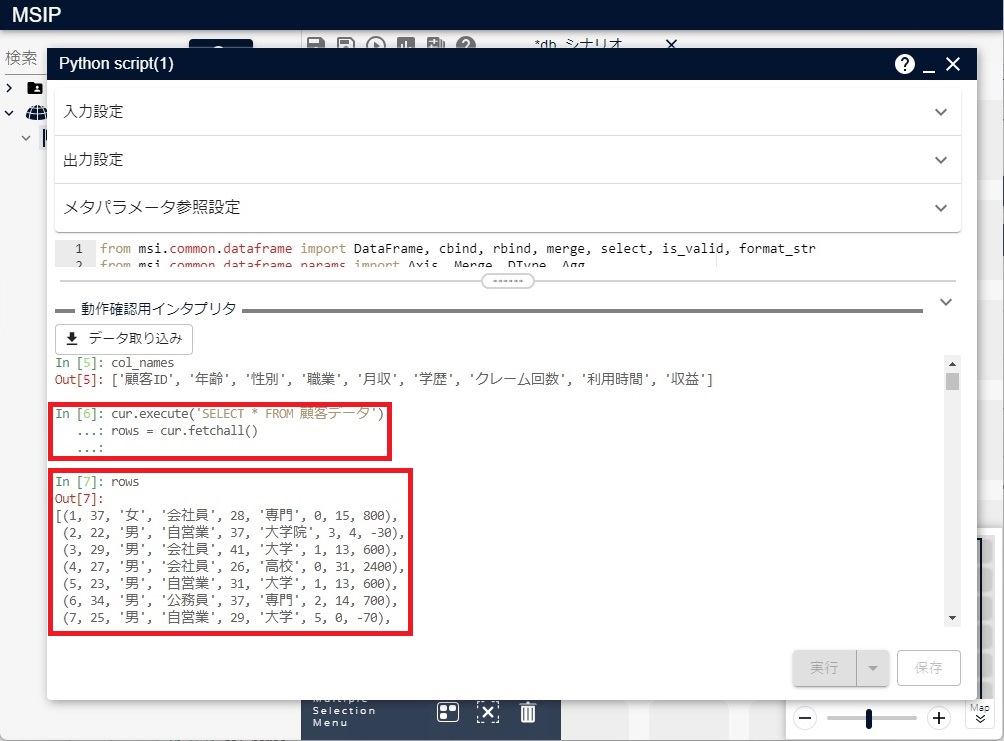
cur.execute('SELECT * FROM 顧客データ')
rows = cur.fetchall()
次の図のようなデータが得られます。
作成したカーソルとコネクションを削除します。
cur.close() conn.close()
このデータとカラム名のリストから、キーが各カラム名、値がカラムの値リストである辞書を、次のように作成します。
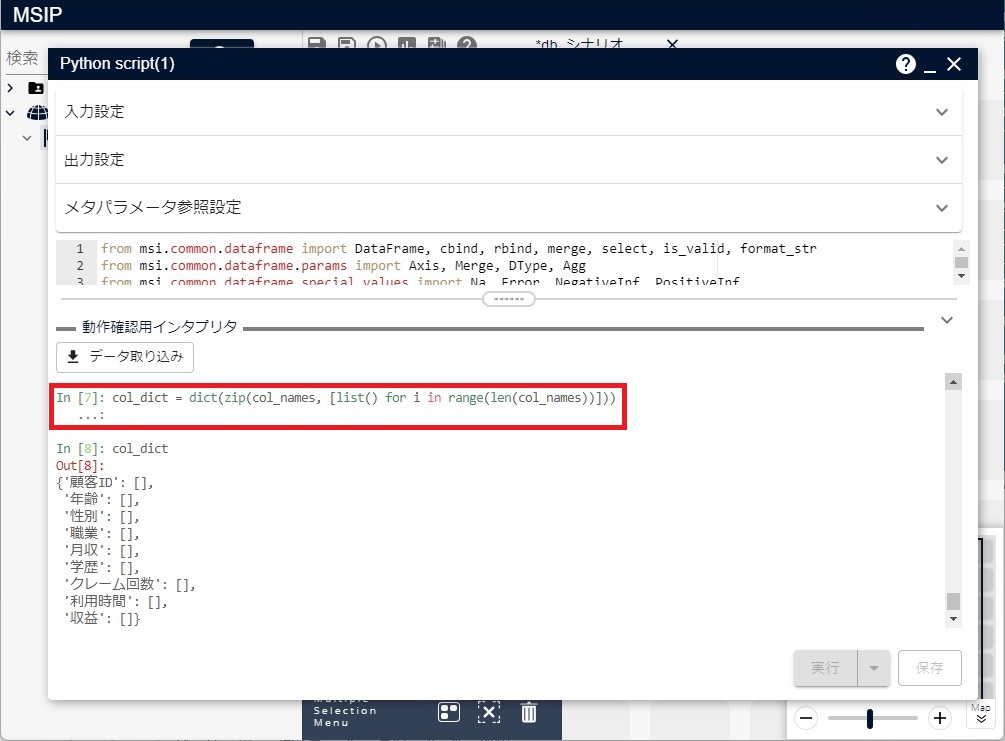
# 値が空リストである辞書を作成します
col_dict = dict(zip(col_names, [list() for i in range(len(col_names))]))
# 各レコードの値を辞書の各リストに追加します
for row in rows:
for (col_name, val) in zip(col_names, row):
col_dict[col_name].append(val)
作成された辞書の内容は、次の図のようになります。
この辞書を基に、DataFrameを作成します。DataFrameの作成方法の詳細については、「MSI DataFrame ドキュメント」の「msi.common.dataframe module」内の「msi.common.dataframe.dataframe.DataFrame」を参照ください。
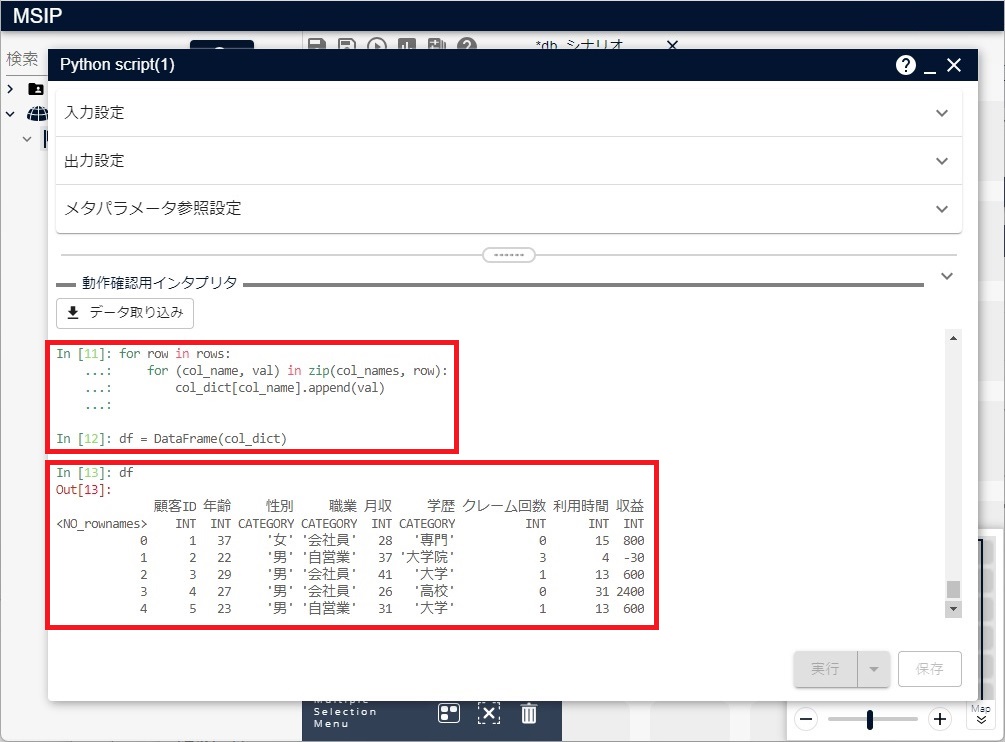
df = DataFrame(col_dict)
作成されたDataFrameの内容は、次の図のようになります。
上記のPythonコードをまとめて、データベースのデーブルの内容を格納したDataFrameをPythonアイコンの結果にするコードを示します。
import pyodbc
from msi.common.dataframe import DataFrame
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
cur = conn.cursor()
cur.execute("DESC 顧客データ")
col_descs = cur.fetchall()
col_names = [col[0] for col in col_descs]
cur.execute('SELECT * FROM 顧客データ')
rows = cur.fetchall()
cur.close()
conn.close()
col_dict = dict(zip(col_names, [list() for i in range(len(col_names))]))
for row in rows:
for (col_name, val) in zip(col_names, row):
col_dict[col_name].append(val)
result = DataFrame(col_dict)
次の図のように、上記のソースコードをコピーし、Pythonアイコン上にペーストします。
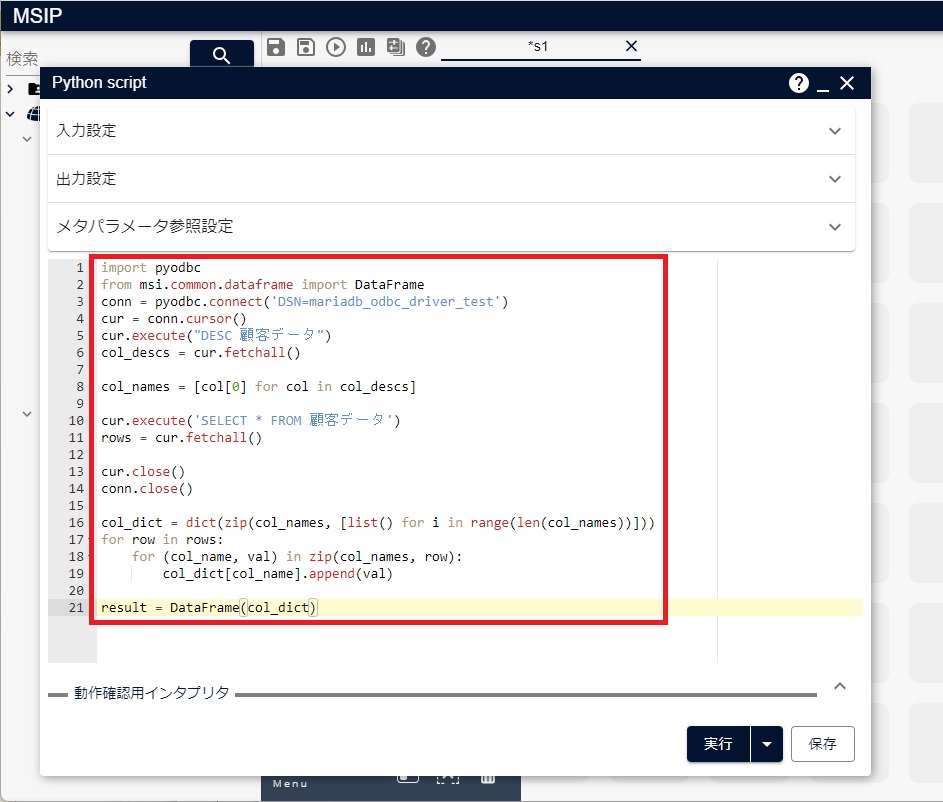
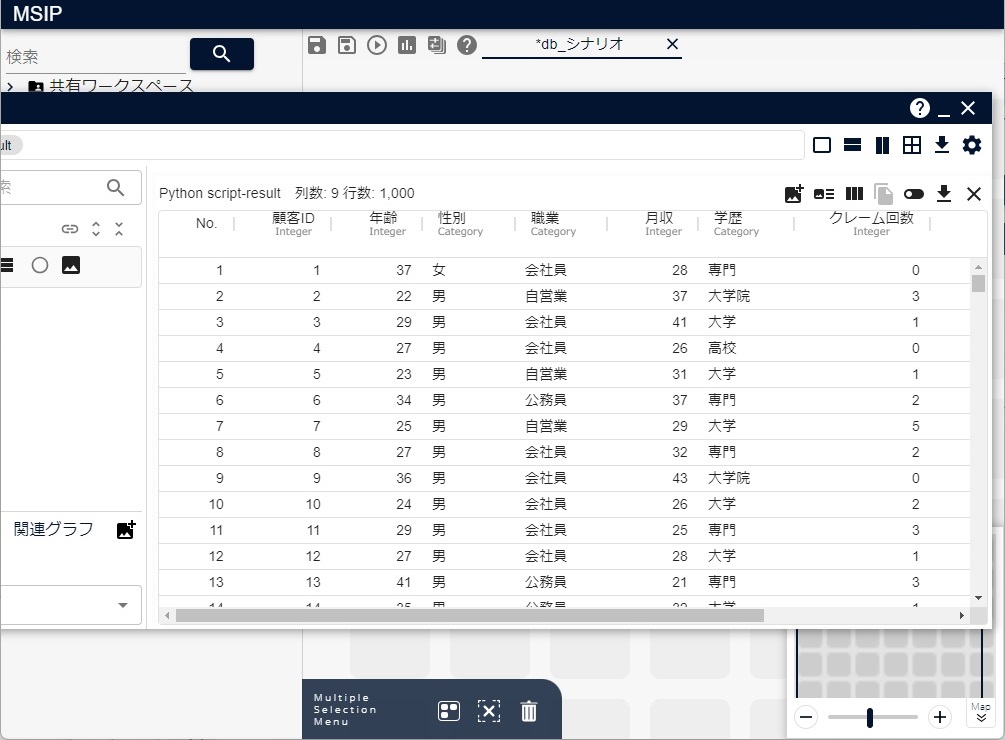
実行すると、テーブルの内容が、次の図のようにPythonアイコンの結果として得ることができます。
3.2.4. データベースから読み込んだデータからpandasデータを作成する
作成したコネクションを利用して、SQLの結果を基にpandasデータを作成する方法を説明します。SQLの結果を基にpandasデータを作成するために、pandasの関数read_sql_queryを利用します。関数read_sql_queryの詳細についてはpandas.read_sql_query(2023/09/01現在)を参照ください[外部のWebサイトに移動します]。
この例では、テーブル「顧客データ」を利用します。
import pyodbc
# pandasを利用できるようにします
import pandas
# データソースを指定してDMBSに接続し、コネクションを作成します
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
# 作成したコネクションを利用して、指定されたテーブルを実行し、
# 結果が格納されたpandasデータを得ます
pd_df = pandas.read_sql_query('SELECT * FROM 顧客データ', conn)
# 作成したコネクションを削除します
conn.close()
次の図のようなデータが得られます。
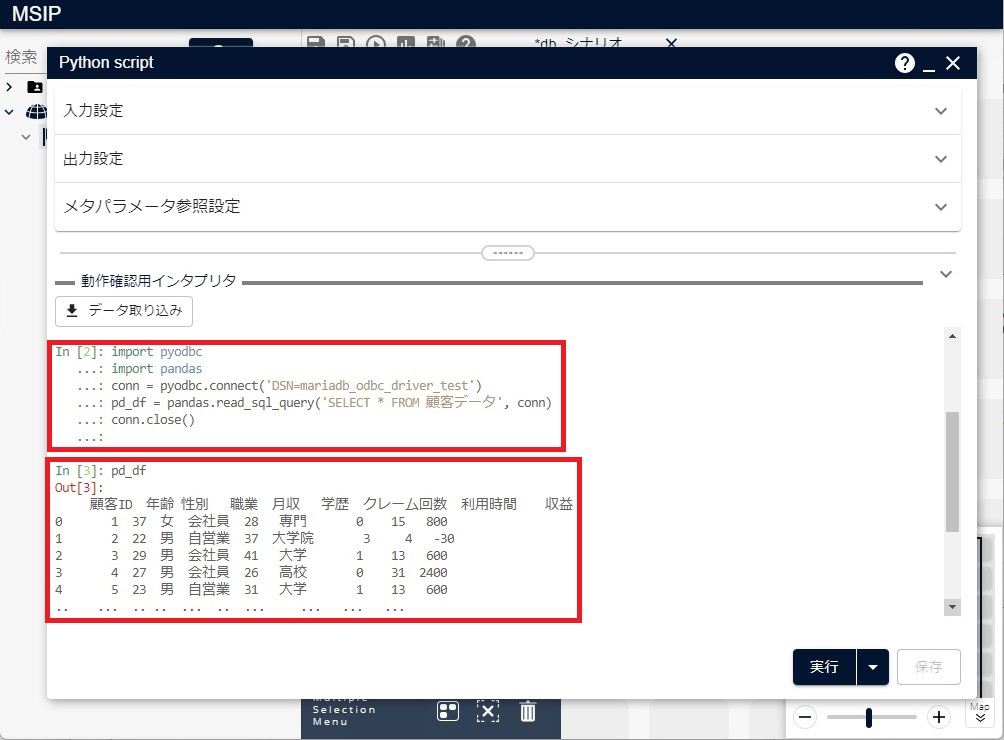
このpandasデータをPythonアイコンの出力にするには、pandasデータからDataFrameを作成する必要があります。pandasデータからDataFrameを作成するには、pandas_to_dataframeを利用します。関数pandas_to_dataframeの詳細については、「MSI DataFrame ドキュメント」の「msi.common.dataframe module」内の「msi.common.dataframe.dataframe.pandas_to_dataframe」を参照ください。
# pandas_to_dataframeを利用できるようにします from msi.common.dataframe.dataframe import pandas_to_dataframe # pandasデータからDataFrameを作成します df = pandas_to_dataframe(pd_df)
作成されたDataFrameの内容は、次の図のようになります。
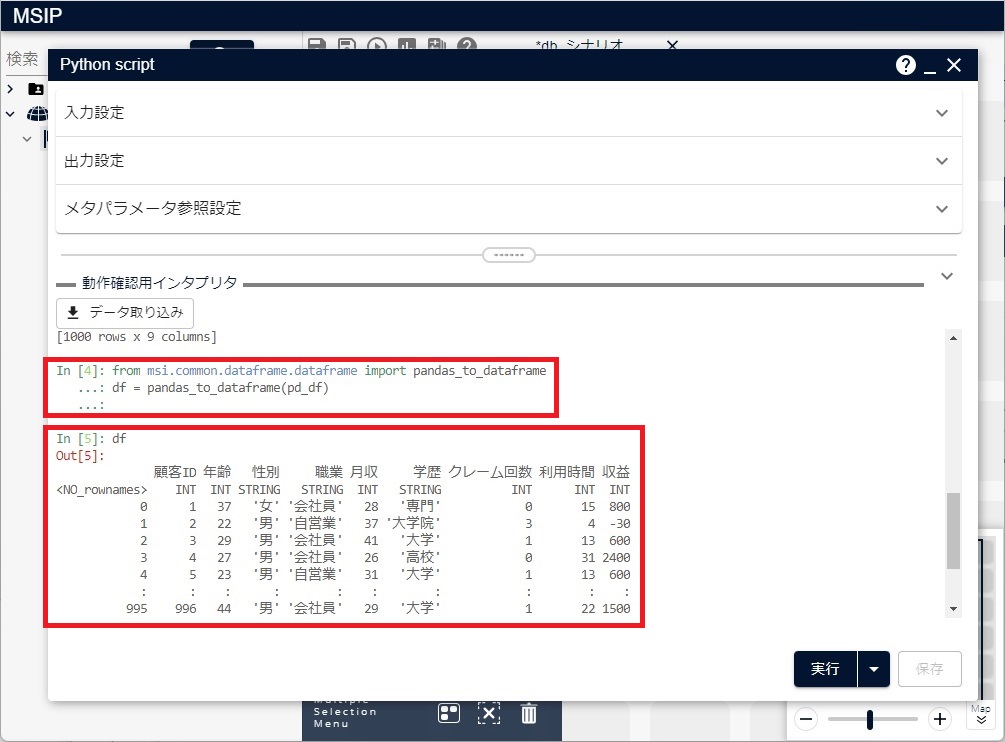
上記のPythonコードをまとめて、read_sql_queryを利用してデータベースのデーブルの内容を読み込むコードを示します。
import pyodbc
import pandas
from msi.common.dataframe.dataframe import pandas_to_dataframe
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
pd_df = pandas.read_sql_query('SELECT * FROM 顧客データ', conn)
conn.close()
result = pandas_to_dataframe(pd_df)
次の図のように、上記のソースコードをコピーし、Pythonアイコン上にペーストします。
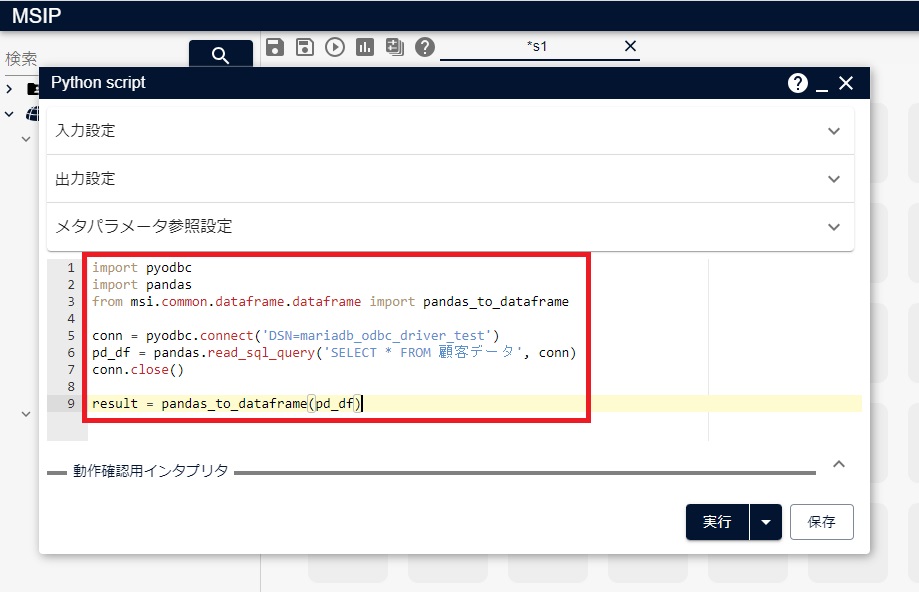
実行すると、テーブルの内容がPythonアイコンの結果として得ることができます。
3.2.5. データベースのデータを更新する
データベースに対してSQLを実行することで、データの追加・更新・削除することができます。たとえば、次のSQLを実行して、テーブル「顧客データ」のカラム「学歴」内の「専門」を「専門学校」に更新する例を説明します。 なお、例示した内容を実行するとデータベース内のデータが変更されますのでご注意ください。
カラム「学歴」内の「専門」を「専門学校」に更新するには、次のSQLを実行します。
UPDATE 顧客データ SET 学歴 = "専門学校" WHERE 学歴 = "専門"
そこで、最初にこのSQLを実行します。その後、SQLの実行結果を確定するために、コネクションのcommitを実行します。
import pyodbc
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
cur = conn.cursor()
# 更新SQLを実行します
cur.execute('UPDATE 顧客データ SET 学歴 = "専門学校" WHERE 学歴 = "専門"')
# 実行結果を確定します
conn.commit()
cur.close()
conn.close()
Pythonアイコンで実行する場合は、Pythonアイコンの入力設定のtableと出力設定のresultは不要なので削除します。
次の図のように、上記のソースコードをコピーし、Pythonアイコン上にペーストします。
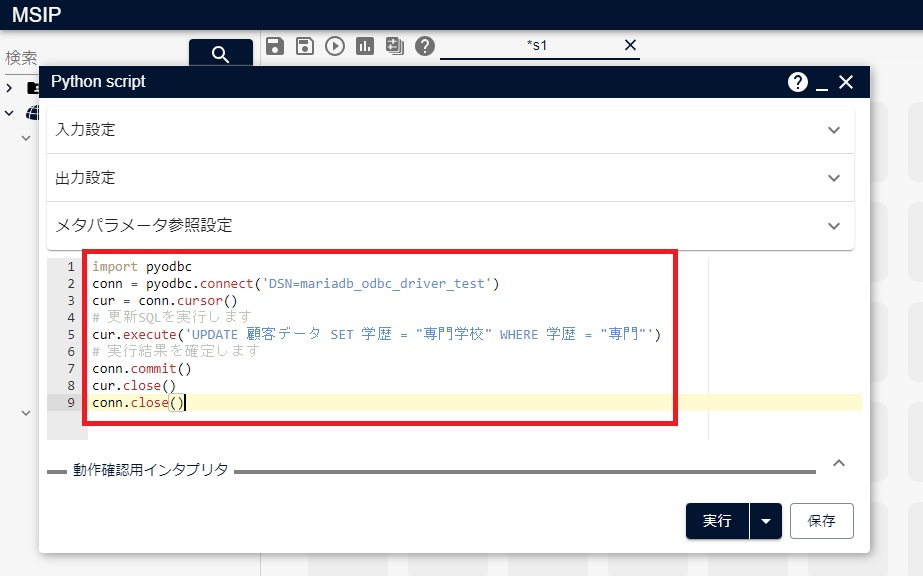
3.2.3. データベースから読み込んだデータからPythonアイコンの出力を作成するなどの方法でテーブルの内容を再取得すると、カラム「学歴」内の「専門」が「専門学校」に更新されていることが、次の図のように確認できます。
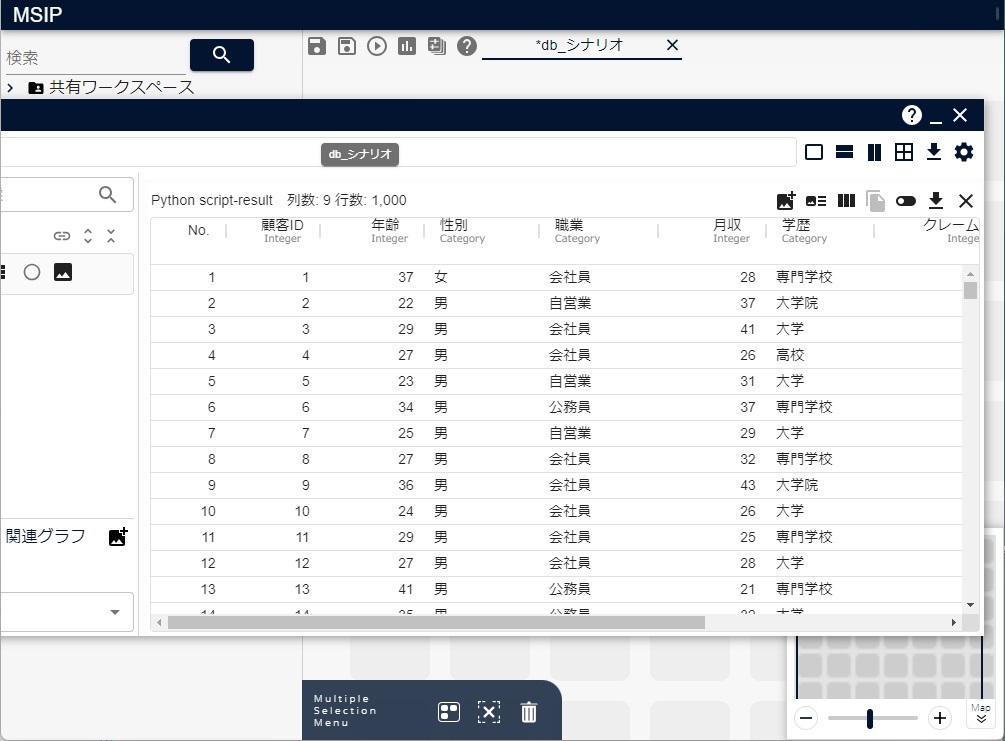
3.2.6. データベースにデータを追加する
テーブル「顧客データ」に複数のレコードデータを追加する例を説明します。 本説明の内容を実行するとデータベース内のデータが変更されますのでご注意ください。
追加する際は、複数のレコードデータを一度に追加するバルクインサートを利用します。バルクインサートを利用する際は、次のようなSQLを発行します。
INSERT INTO 顧客データ(顧客ID, 年齢, 性別, 職業, 月収, 学歴, クレーム回数, 利用時間, 収益) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
このSQLと、追加対象の複数のレコードデータを組み合わせて指定して実行します。バルクインサートを利用すると、各レコードごとに追加する場合と比べて、効率よく処理することができるため、処理時間を短縮できます。
まず、追加するデータとして、次の図のようなデータを持つテーブルデータを用意します。
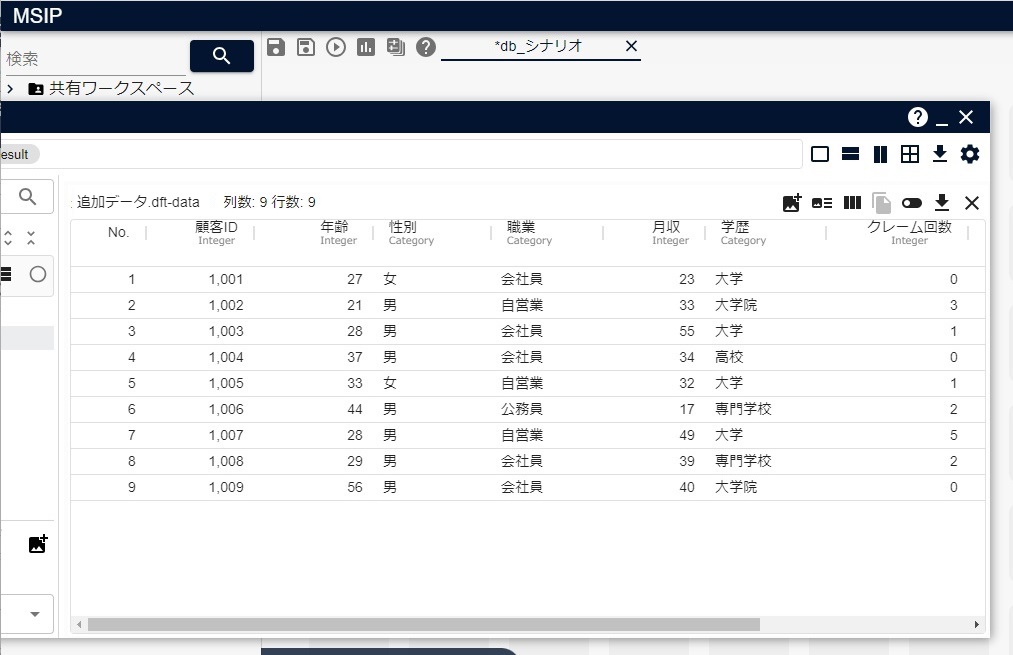
テーブルデータの各列の型は、テーブル「顧客データ」で対応するカラムに格納できる型にします。 この例では、次のように列型を指定します。列名はカラム名と同じにします。
| カラム名/列名 | カラム型 | 列型 |
|---|---|---|
| 顧客ID | int(11) | 整数型 |
| 年齢 | int(11) | 整数型 |
| 性別 | varchar(10) | カテゴリ型 |
| 職業 | varchar(10) | カテゴリ型 |
| 月収 | int(11) | 整数型 |
| 学歴 | varchar(10) | カテゴリ型 |
| クレーム回数 | int(11) | 整数型 |
| 利用時間 | int(11) | 整数型 |
| 収益 | int(11) | 整数型 |
このデータアイコン(この例では「追加データ.dft」)を入力とするPythonアイコンを、次の図のように作成します。
作成したPythonアイコンで、次のようなPythonコードを定義します。バルクインサートにはexecutemanyを利用します。
import pyodbc
conn = pyodbc.connect('DSN=mariadb_odbc_driver_test')
cur = conn.cursor()
# バルクインサートのSQLを用意します
sql = 'INSERT INTO 顧客データ(顧客ID, 年齢, 性別, 職業, 月収, 学歴, クレーム回数, 利用時間, 収益) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)'
# 高速でexecutemanyを実行するよう指定します
cur.fast_executemany = True
# 1回のexecutemanyで最大何行分を追加するか指定します
insert_size = 1000
for row_id in range(0, table.nrow(), insert_size):
# 1回のexecutemanyでインサートするデータを保持するリストを用意します
rows = []
for ri in range(row_id, row_id + insert_size):
# 各行のインサートデータを用意します
if ri >= table.nrow():
break
# 対象行の各列の値を取得します
row_data = [table.get_value(ri, ci) for ci in range(table.ncol())]
# 取得した各列の値をタプルとしてインサートデータに追加します
rows.append(tuple(row_data))
# 用意した1回分のインサートデータを追加します
cur.executemany(sql, rows)
conn.commit()
cur.close()
conn.close()
次の図のように、上記のソースコードをコピーし、Pythonアイコン上にペーストします。
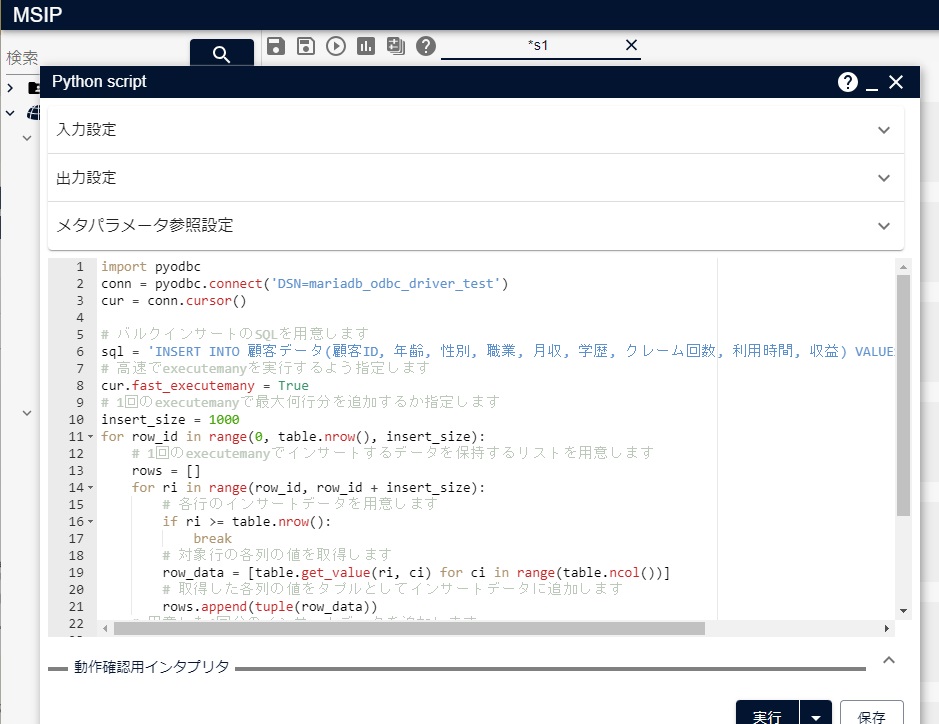
Pythonアイコンで実行する場合は、Pythonアイコンの出力設定のresultは不要なので削除します。
テーブルの内容を再取得すると、次の図のように、テーブルにデータが追加されてることが確認できます。