交差検証でモデルを評価したい
交差検証を行い、モデルを評価するためのスクリプトの例示をします。交差検証スコアとMSIPで利用可能なモデルを出力します。
説明
交差検証は教師あり学習モデルの汎化性能を評価するための手法です。 交差検証では、データをいくつかのブロックに分割し、1つのブロックを除いたデータで学習を行い、除いた1つのブロックで検証を行うことを繰り返します。
MSIP の「最適化機能」では、交差検証を行いハイパーパラメータのチューニングを行うことが出来ますが、ハイパーパラメータを明示的に与えて精度評価を行うことは難しいです。
本記事では、MSIPのPython script機能を利用して、比較的簡単にモデルの汎化性能を評価するために交差検証を行う方法を記載します。
本記事で作成する交差検証のための Python script は次のような入出力と設定画面です。
入力
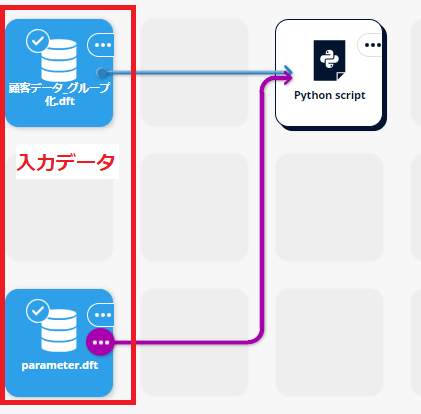
- 交差検証を行いたいデータ(学習用データ)
- 交差検証用のハイパーパラメータを記載したテーブル
出力
- 交差検証の結果を出力したテーブル (result テーブル)

- 各交差検証で利用したモデルのリスト

注1
モデルを出力するにはPython scriptを実行後、「実行結果をデータリソースとして登録」をクリックしてください。
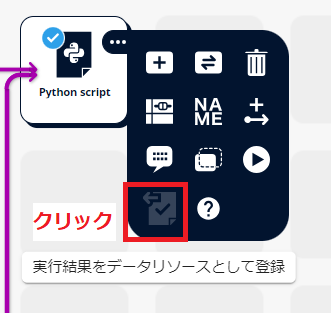
注2
result テーブルのNo.列は1始まりですが、出力されるモデルのインデックスは0始まりであることに注意してください。
例えば、テーブルで4行目のモデルを利用したい場合は、インデックスが3のモデルを利用します。

作成済みシナリオ
作成済みのシナリオはこちらからダウンロードができます。
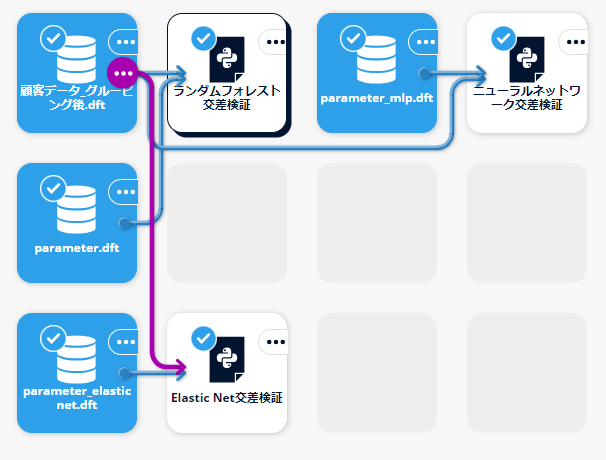
このシナリオ内の Python script(ランダムフォレスト交差検証、ニューラルネットワーク交差検証、Elastic Net交差検証)の作成方法について、以下では解説します。
以下の項目については読まずとも、作成済みシナリオをダウンロードすれば、交差検証の実行は可能です。
- スクリプトの作成方法やスクリプトの概要を知りたい
- 異なるモデルやパラメータを与えたい
場合は、以下をお読みください。
使い方
前提
- まず初めに作成済みシナリオ内の「ランダムフォレスト交差検証」の作成方法について説明します。パラメータの変更方法やその他のモデルでの交差検証方法については、「分析への応用」の項目で説明します。
- ランダムフォレストは scikit-learn のランダムフォレスト(
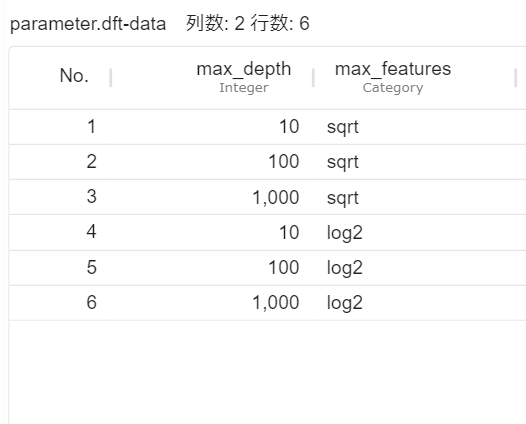
sklearn.ensemble.RandomForestClassifier)を利用します。scikit-learn のランダムフォレストをMSIPで利用可能な分析モデルにする加工をして出力しています。 - パラメータのテーブルデータは、
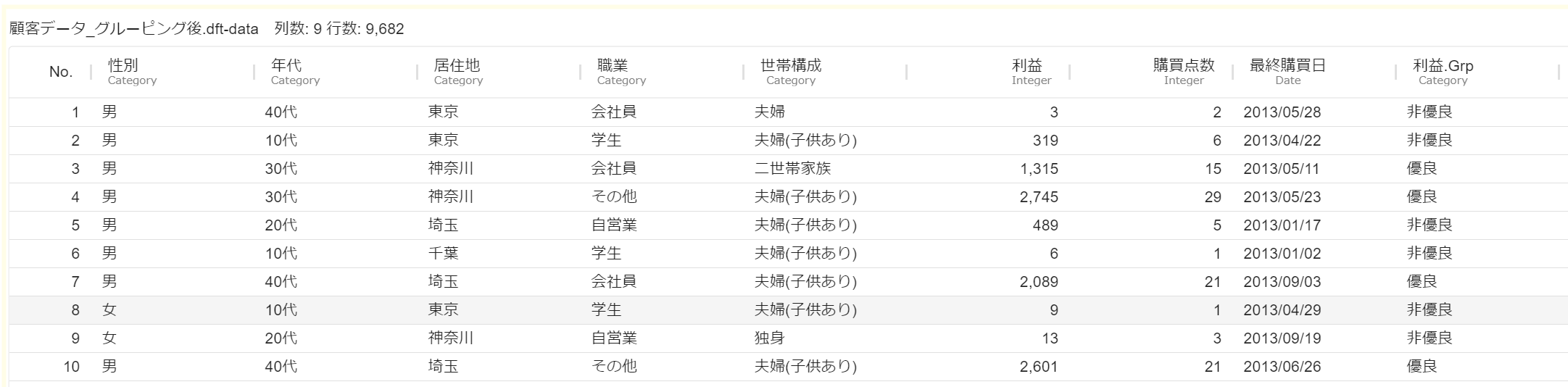
sklearn.ensemble.RandomForestClassifierの引数を列名とするテーブルデータです。パラメータのテーブルデータの例(parameter.dft)はこちらからダウンロードが可能です。パラメータの列名は、sklearn.ensemble.RandomForestClassifierの引数に対応します。sklearn.ensemble.RandomForestClassifierの引数はこちらのscikit-learnのマニュアルから確認ができます。 - 交差検証に利用するデータは、顧客データ.dft の目的変数をグループ化したものです。交差検証に利用するデータ(
顧客データ_グループ化.dft)はこちらからダウンロードが可能です。
1. Python script の配置と入出力設定
顧客データ_グループ化.dft をMSIPにアップロードし、シナリオエリアに配置します。
「ノードを追加」を選択し、Python scriptを配置します。

Python scriptのパラメータ設定画面を開き次のように入出力を設定します。
- 入力
- 名前:table, 型:table
- 名前:parameter, 型:table
- 出力
- 名前:result, 型:table
- 名前:models, 型:model[]
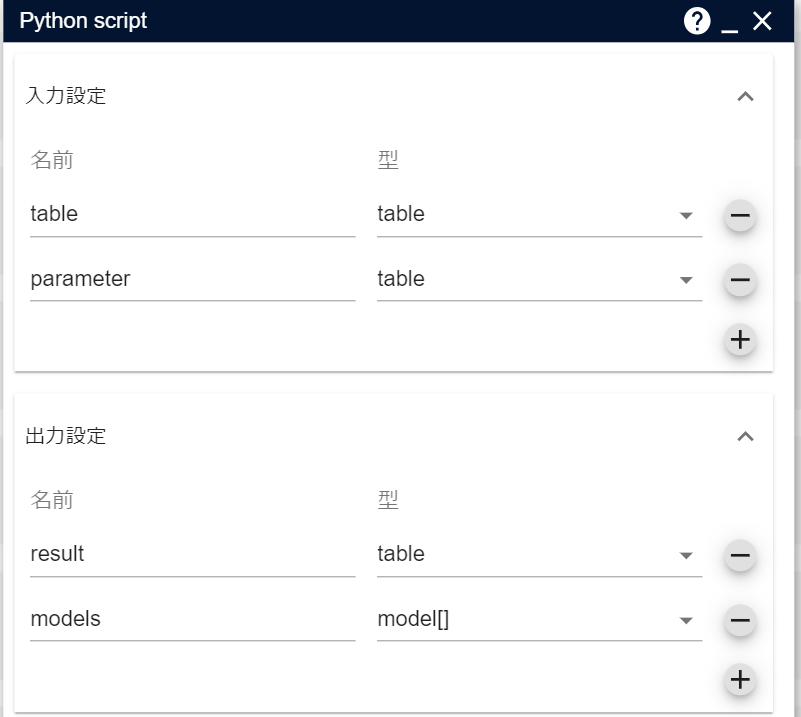
入力のtableは、学習用のテーブルデータに対応し、parameterはハイパーパラメータに対応します。
出力のresultは、各々のハイパーパラメータに対する交差検証スコアのテーブルです。model[]は予測モデルをAlkanoで使用可能なモデルに変換したモデルのリストです。
2. インプット設定
parameter.dft をアップロードし、シナリオエリアに配置します。parameter.dft から、Python script にリンクを追加します。
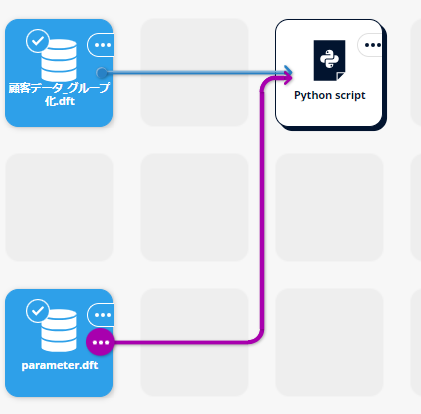
Python script の「インプット設定」から、Input Matching Controller を開き、table に学習用データ、parameter にパラメータのデータが対応しているかを確認してください。

3. スクリプトの記述
Python script のパラメータ設定画面を開きます。
下記のスクリプトをスクリプト欄に貼り付けてください。 スクリプトでは次の処理が行われています。
- パラメータ設定画面の GUI の作成
- 入力したパラメータのテーブルの1行ごとに交差検証を行い、交差検証スコアとモデルを作成する
- 交差検証スコアを行方向に結合して
table型で出力する。モデルはmodel[]型で出力する
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score, KFold
from sklearn.preprocessing import OneHotEncoder
from msi.vms.sklearn_model import SklearnClassifier
from msi.icons.vms.predict_sklearn_model import SklearnClassifierPredict
from msi.common.dataframe.dataframe import pandas_to_dataframe
from sklearn.pipeline import Pipeline
# 交差検証の分割数
# MSIP_GUI_Definition_v1.0.0
n_splits = 5 # { "type": "integer", "title": "分割数", "comment": "交差検証の分割数。2以上を指定してください。" }
score = "roc_auc" # { "type": "category", "title": "スコア", "comment": "スコアリングに利用する評価指標を選択してください。", "list": [{ "name": "Accuracy", "value": "accuracy" }, { "name": "AUC", "value": "roc_auc" }] }
var1 = {"obj":[{"name":"利益.Grp","type":"category"}],"exp":[{"name":"性別","type":"category"},{"name":"年代","type":"category"},{"name":"居住地","type":"category"},{"name":"職業","type":"category"},{"name":"世帯構成","type":"category"}]} # { "type": "variable", "title": "変数1", "table": "table", "columns": [{ "title": "目的変数", "field": "obj" }, { "title": "説明変数", "field": "exp" }] }
# MSIP_GUI_Definition_v1.0.0
# 説明変数の列名
Xcols = [var1["exp"][i]["name"] for i in range(len(var1["exp"]))]
# 目的変数の列名
ycol = var1["obj"][0]["name"]
# pandas のデータフレームへ変換します。
df = table.to_pandas()
parameter = parameter.to_pandas()
# Xは説明変数のデータ
X = df[Xcols]
# yは目的変数のデータ
y = df[ycol]
# 交差検証のスコアを保持するテーブル用のリスト
out_table_list = []
# 交差検証に利用したモデルを保持するためのリスト
models = []
for param_dict in parameter.to_dict(orient="records"):
# パイプラインでモデルを一纏めにします
_pipeline = Pipeline(
[
# one-hot エンコーディングを行い、カテゴリ列を数値列に直します
('encoder', OneHotEncoder()),
# RandomForest を用いて分類を行います
('random_forest',RandomForestClassifier(**param_dict))
]
)
# n_splits 分割交差検証を行う
kfold = KFold(n_splits=n_splits)
cv_score = cross_val_score(estimator=_pipeline,X=X,y=y,scoring=score,cv=kfold)
# 交差検証の結果をdictionaryに格納
out_dict = {
**param_dict,
"スコア平均":cv_score.mean(),
"スコア標準偏差":cv_score.std(),
**{
f"スコア{n+1}": cv_score[n] for n in range(len(cv_score))
}
}
# 交差検証の結果をリストに格納
out_table_list.append(out_dict)
# 交差検証の結果をログに出力
print(out_dict)
# sklearn のモデル(パイプライン)を Alkano で利用するモデルに変換し、入力データを適用
_wrapped_model = SklearnClassifier(_pipeline)
_wrapped_model.fit(table, ycol=ycol, Xcols=Xcols)
model = SklearnClassifierPredict(_wrapped_model, include_original_input=True)
# 適用後のデータをリストに格納
models.append(model)
# 交差検証の結果をデータフレームに格納
result = pandas_to_dataframe(pd.DataFrame(out_table_list))
スクリプトを貼り付けたら、パラメータ設定画面の保存ボタンを押します。
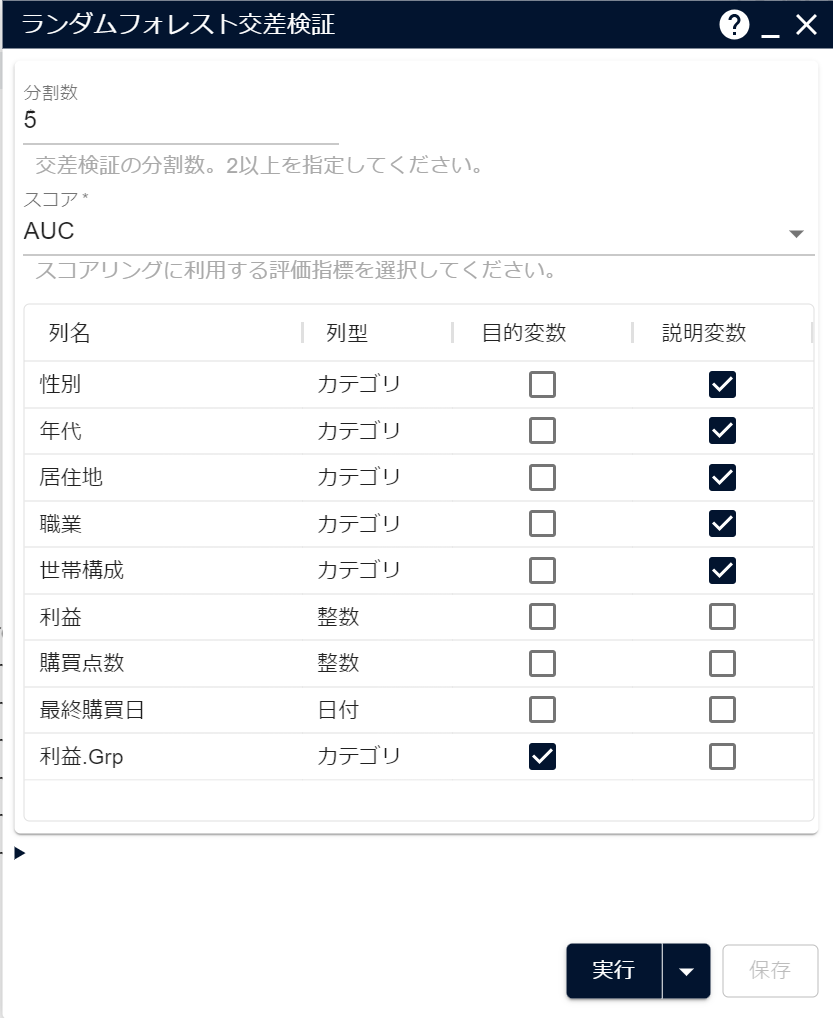
画像のようにパラメータ設定画面にGUIが作成されます。GUIが作成されたら「実行」をクリックしてください。
4. 実行結果とモデルの確認
可視化画面から実行結果が確認できます。
実行結果のテーブル(result)の列構成は下記です。
- 入力のパラメータ
- 交差検証スコアの平均、標準偏差
- 各試行での交差検証スコア(スコア1~スコアN)(Nはパラメータ画面の分割数)
「実行結果をデータリソースとして登録」をクリックすることで構築したモデルがMSIP画面左のワークスペースブラウザに出力されます。

予測結果が良かったモデルをシナリオ上に配置して利用することが可能です。
分析への応用
交差検証のスクリプトの応用として次の2パターンがあります。
- ハイパーパラメータのみを変える
- 教師あり学習に用いるアルゴリズムを変える
それぞれについて解説します。
ハイパーパラメータのみを変える
- パラメータの値のみを変える
- 与えるパラメータの種類を変える
という2パターンについて解説します。
パラメータの値のみを変える
用意する csv ファイルの1行目(列名)はパラメータ名とします。
例えば、max_depth=10000, max_features=sqrtというパラメータで試したい場合は、次のようなcsvファイルを作成して、データをアップロードします。
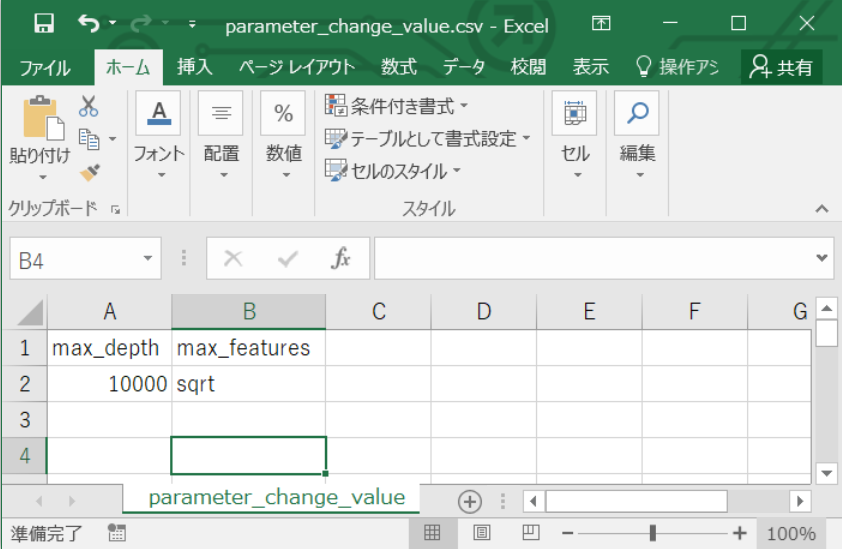
作成した Python script の parameter の入力を新たに作成したパラメータファイル差し替えます。
新しい値のパラメータのcsvファイルをMSIPにアップロードし、シナリオ上に配置し、リンクを接続します。
Python script の インプット設定から、Input Matching Controller を開き、Python script の入力のパラメータを新しいパラメータの dft に紐づけます。
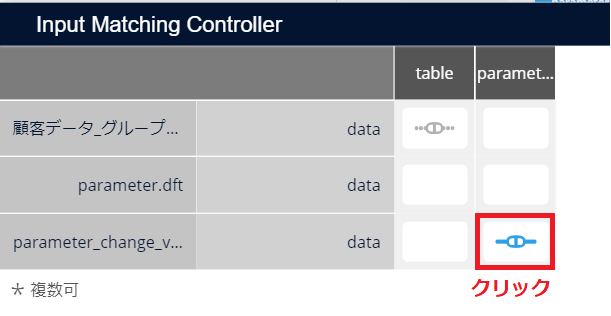
この状態でPython scriptを実行をします。
実行が終了したら可視化画面を確認します。 Python script の result テーブルを確認します。新しいパラメータに対して交差検証スコアが算出されます。
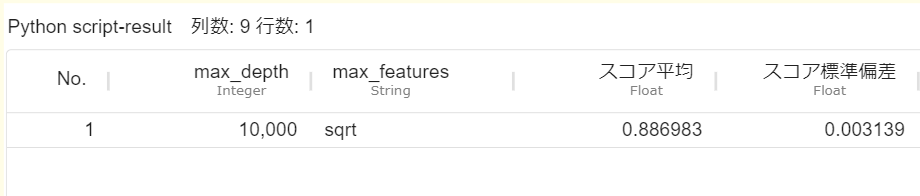
新しいパラメータの予測モデルを利用する場合も同様に、「実行結果をデータリソースとして登録」をクリックし、構築したモデルをMSIP画面左のワークスペースブラウザに出力します。 出力したモデルをシナリオエリアに配置して、利用することが可能です。
与えるパラメータの種類を変える
用意する csv ファイルの1行目(列名)はパラメータ名とします。
ランダムフォレストのハイパーパラメータをn_estimators=70, max_depth=100, max_features=sqrtと指定をしたい場合は、次のように n_estimators 列を追加した csv ファイルを作成します。
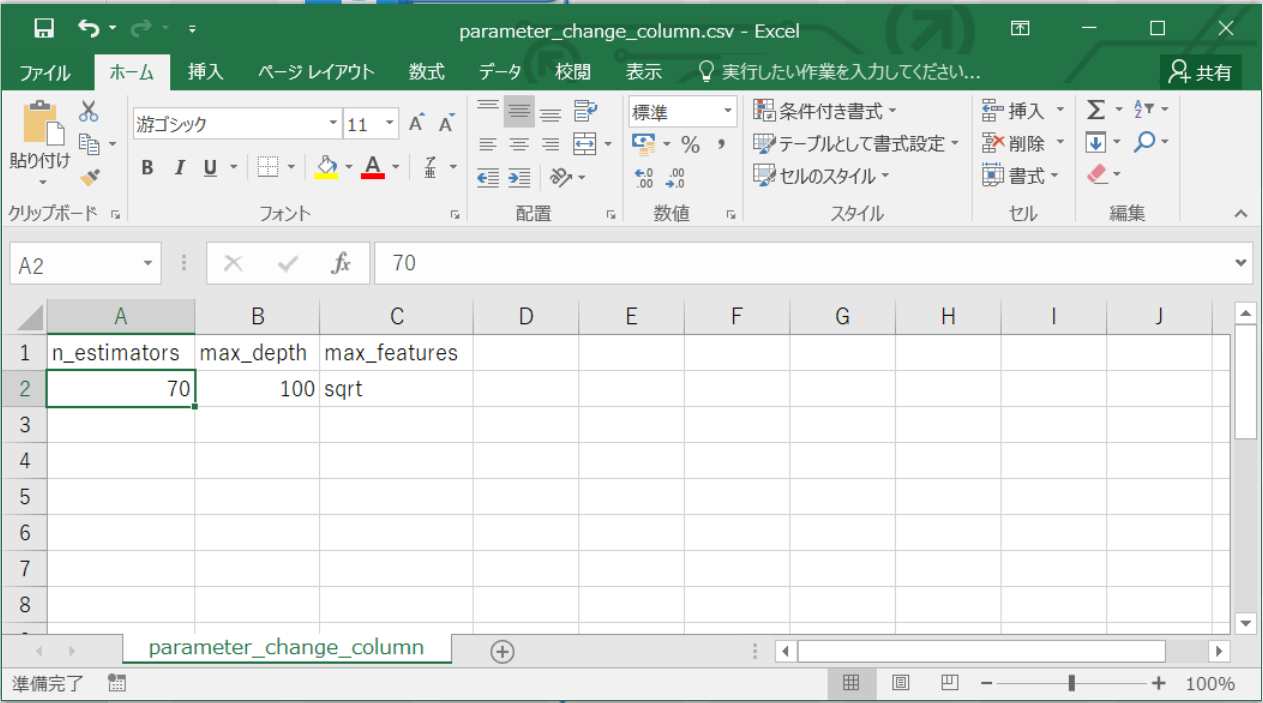
ハイパーパラメータ名は、sklearn.ensemble.RandomForestClassifierの引数名を与えることが出来ます。
例えば、 n_estimators, criterion, max_depth などをパラメータ名として与えることが出来ます。
sklearn.ensemble.RandomForestClassifierで利用可能な引数名(ハイパーパラメータ名)については、sklearn.ensemble.RandomForestClassifierのマニュアルをご参照ください。
作成した csv ファイルを MSIP にアップロードし、シナリオエリアに配置します。
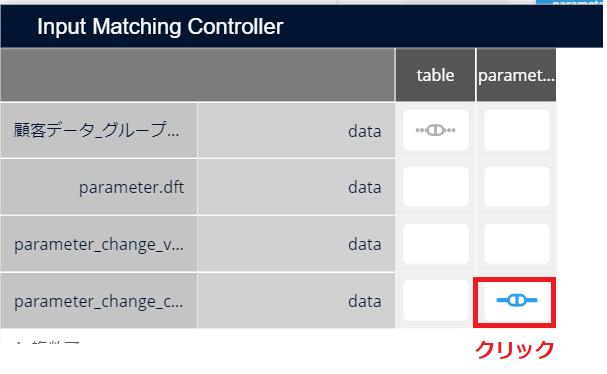
その後リンクを追加し、Python script のインプット設定からInput Matching Controller を開き、parameter 列が新しいパラメータとなるように設定をします。
その後Python scriptを実行します。
実行が終了したら可視化画面を確認します。 Python script の result テーブルを確認します。新しいパラメータに対して交差検証スコアが算出されます。

アルゴリズムを変える
- 分類モデル(目的変数がカテゴリ)でアルゴリズムを変える
- 回帰モデル(目的変数が数値)にする
という2パターンで解説をします。
分類モデルでアルゴリズムを変える場合
以下では、ランダムフォレストの代わりに、ニューラルネットワークで交差検証を行います。
なお、ニューラルネットワークで交差検証を行った例については、作成済みシナリオ内にもスクリプトがあります。
以下では、ランダムフォレストの交差検証するスクリプトからニューラルネットワークで交差検証をするスクリプトに変更するときの変更箇所について、説明します。
分類モデルのまま、アルゴリズムを変える場合は、次の3つの部分を変更します。
- パラメータファイル
- スクリプト内のモデルインポート部分
- スクリプト内のモデル宣言部分
scikit-learn のニューラルネットワーク(sklearn.neural_network.MLPClassifier)を例にアルゴリズムを変更する手順を説明します。
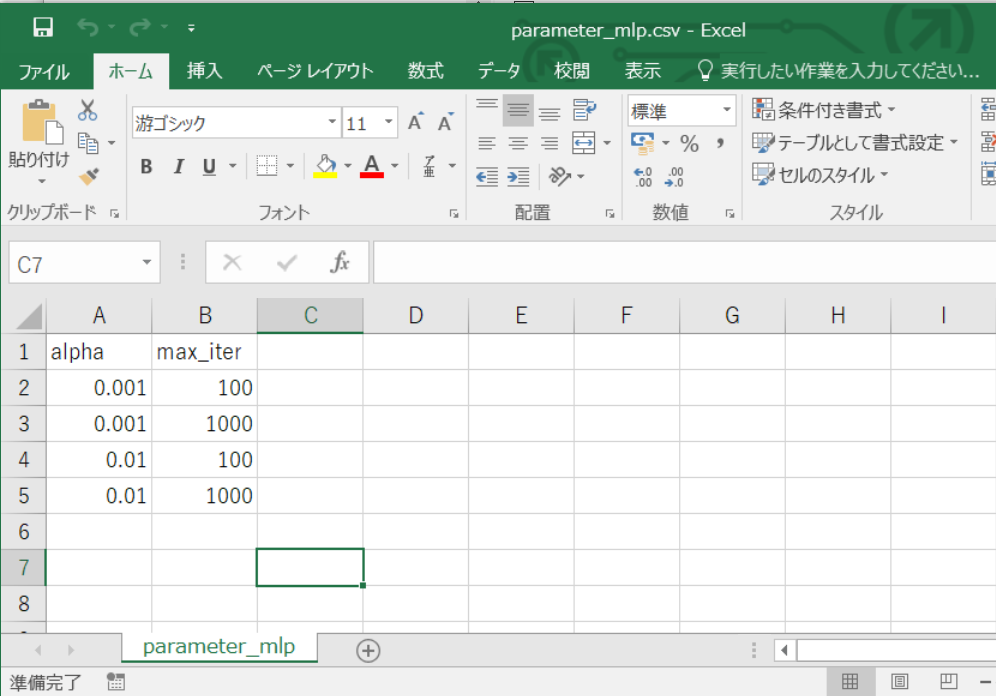
- パラメータのcsvファイル(parameter_mlp.csv)を作成します。与えるパラメータは、sklearn.neural_network.MLPClassifier のマニュアルの引数に記載のものとします。今回は、
alphaとmax_iterをパラメータとして与えます。
パラメータのcsvファイルをMSIPにアップロードし、シナリオエリアに配置します。

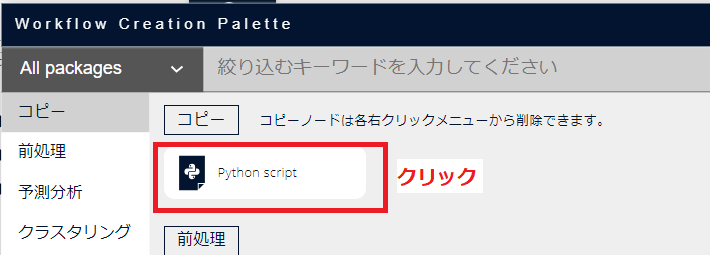
- ランダムフォレストで交差検証を行った Python script ノードをコピーします。
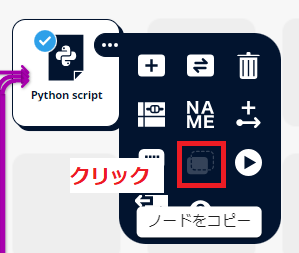
学習用のデータ(顧客データ_グループ化.dft)からリンクを追加して、コピーした Python script を配置します。
シナリオエリアに配置したパラメータ(parameter_mlp.dft)から「リンクを追加」して Python script に繋げます。
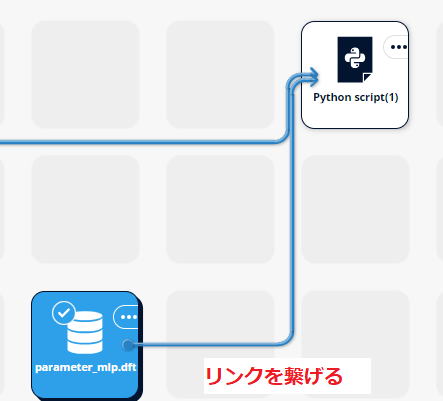
パラメータ設定画面を開きます。
ランダムフォレストで交差検証を行うスクリプト内で、sklearn.ensemble.RandomForestClassifierをインポートしていた部分を、sklearn.neural_network.MLPClassifierをインポートするように書き替えましょう。
before(2行目)
from sklearn.ensemble import RandomForestClassifier
↓ after
from sklearn.neural_network import MLPClassifier
RandomForestClassifierを宣言していた部分をMLPClassifierに書き替えます。
before(46,47行目)
# RandomForest を用いて分類を行います
('random_forest',RandomForestClassifier(**param_dict))
↓ after
# MLPClassifier を用いて分類を行います
('mlp',MLPClassifier(**param_dict))
最終的には、次のようなスクリプトになります。
import pandas as pd
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import cross_val_score, KFold
from sklearn.preprocessing import OneHotEncoder
from msi.vms.sklearn_model import SklearnClassifier
from msi.icons.vms.predict_sklearn_model import SklearnClassifierPredict
from msi.common.dataframe.dataframe import pandas_to_dataframe
from sklearn.pipeline import Pipeline
# 交差検証の分割数
# MSIP_GUI_Definition_v1.0.0
n_splits = 5 # { "type": "integer", "title": "分割数", "comment": "交差検証の分割数。2以上を指定してください。" }
score = "roc_auc" # { "type": "category", "title": "スコア", "comment": "スコアリングに利用する評価指標を選択してください。", "list": [{ "name": "Accuracy", "value": "accuracy" }, { "name": "Recall", "value": "recall" }, { "name": "Precision", "value": "precision" },{ "name": "F1 Score", "value": "f1_score" }, { "name": "AUC", "value": "roc_auc" }] }
var1 = {"obj":[{"name":"利益.Grp","type":"category"}],"exp":[{"name":"性別","type":"category"},{"name":"年代","type":"category"},{"name":"居住地","type":"category"},{"name":"職業","type":"category"},{"name":"世帯構成","type":"category"}]} # { "type": "variable", "title": "変数1", "table": "table", "columns": [{ "title": "目的変数", "field": "obj" }, { "title": "説明変数", "field": "exp" }] }
# MSIP_GUI_Definition_v1.0.0
# 説明変数の列名
Xcols = [var1["exp"][i]["name"] for i in range(len(var1["exp"]))]
# 目的変数の列名
ycol = var1["obj"][0]["name"]
# pandas のデータフレームへ変換します。
df = table.to_pandas()
parameter = parameter.to_pandas()
# Xは説明変数のデータ
X = df[Xcols]
# yは目的変数のデータ
y = df[ycol]
# 交差検証のスコアを保持するテーブル用のリスト
out_table_list = []
# 交差検証に利用したモデルを保持するためのリスト
models = []
for param_dict in parameter.to_dict(orient="records"):
# パイプラインでモデルを一纏めにします
_pipeline = Pipeline(
[
# one-hot エンコーディングを行い、カテゴリ列を数値列に直します
('encoder', OneHotEncoder()),
# MLPClassifier を用いて分類を行います
('mlp',MLPClassifier(**param_dict))
]
)
# n_splits 分割交差検証を行う
kfold = KFold(n_splits=n_splits)
cv_score = cross_val_score(estimator=_pipeline,X=X,y=y,scoring=score,cv=kfold)
# 交差検証の結果をdictionaryに格納
out_dict = {
**param_dict,
"スコア平均":cv_score.mean(),
"スコア標準偏差":cv_score.std(),
**{
f"スコア{n+1}": cv_score[n] for n in range(len(cv_score))
}
}
# 交差検証の結果をリストに格納
out_table_list.append(out_dict)
# 交差検証の結果をログに出力
print(out_dict)
# sklearn のモデル(パイプライン)を Alkano で利用するモデルに変換し、入力データを適用
_wrapped_model = SklearnClassifier(_pipeline)
_wrapped_model.fit(table, ycol=ycol, Xcols=Xcols)
model = SklearnClassifierPredict(_wrapped_model, include_original_input=True)
# 適用後のデータをリストに格納
models.append(model)
# 交差検証の結果をデータフレームに格納
result = pandas_to_dataframe(pd.DataFrame(out_table_list))
書き替えたら、該当ノードを実行します。
学習済みのモデルを利用する場合は、「実行結果をデータリソースとして登録」をクリックし、構築したモデルをMSIP画面左のワークスペースブラウザに出力します。
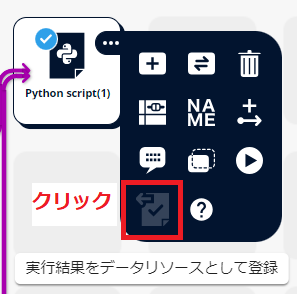

出力したモデルをシナリオエリアに配置して、利用することが可能です。
回帰モデルに変更する場合
以下では、ランダムフォレストの代わりに、Elastic Net の交差検証を行います。
Elastic Net で交差検証を行った例については、作成済みシナリオ内にスクリプトがありますので、ご確認いただけます。
以下では、ランダムフォレストの交差検証するスクリプトから回帰モデルである Elastic Net で交差検証をするスクリプトに変更するときの変更箇所について、説明します。
Elastic Net は、目的変数が数値変数である回帰モデルです。
回帰モデルで交差検証を行う場合は、
- パラメータファイル
- スクリプト内のインポート部分
- スクリプト内のモデル宣言部分
に加えて、次を変更する必要があります。
- Sklearnのラッパークラス
- 評価指標の宣言部分
以下では、scikit-learn のElastic Net (sklearn.linear_model.ElasticNet)を例にモデルの変え方について説明します。
- パラメータのcsvファイル(parameter_elasticnet.csv)を作成します。与えるパラメータは、
sklearn.linear_model.ElasticNetのマニュアルに記載の引数です。今回は、alphaとl1_ratioをパラメータとして与えます。
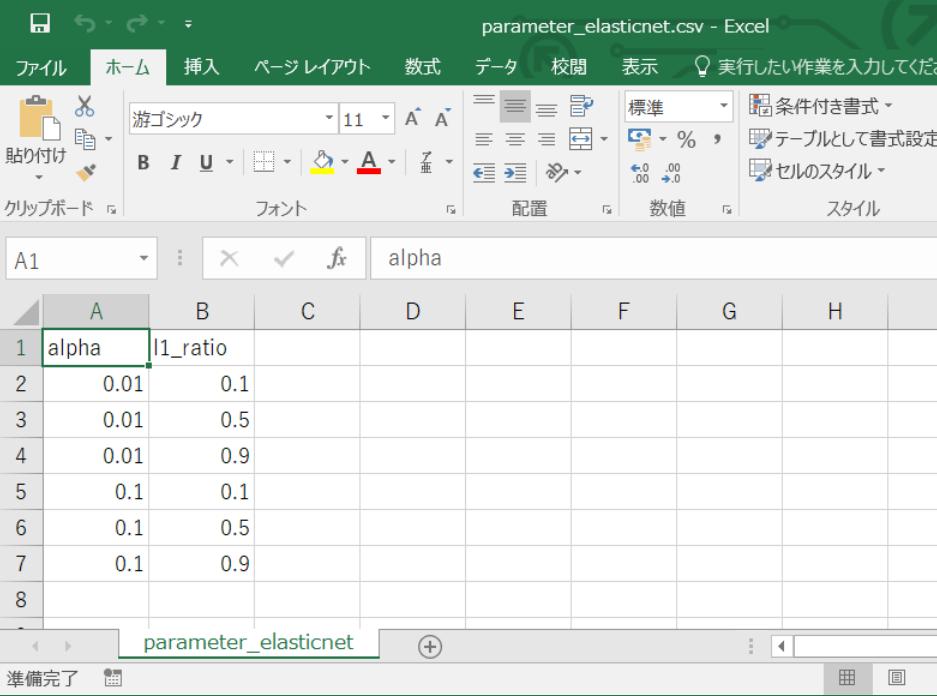
パラメータのcsvファイルをMSIPにアップロードし、シナリオエリアに配置します。

- ランダムフォレストの交差検証を行う Python script ノードをコピーします。
学習用のデータ(顧客データ_グループ化.dft)からリンクを追加して、コピーした Python script を配置します。
シナリオエリアに配置したパラメータ(parameter_elasticnet.dft)から「リンクを追加」して Python script に繋げます。
パラメータ設定画面を開きます。スクリプト内のsklearn.ensemble.RandomForestClassifierをインポートしていた部分を、sklearn.linear_model.ElasticNetをインポートするように書き替えましょう。
before(2行目)
from sklearn.ensemble import RandomForestClassifier
↓ after
from sklearn.linear_model import ElasticNet
RandomForestClassifierを宣言していた部分をElasticNetに書き替えます。
before(46,47行目)
# RandomForest を用いて分類を行います
('random_forest',RandomForestClassifier(**param_dict))
↓ after
# Elastic Net を用いて回帰を行います
('elastic_net',ElasticNet(**param_dict))
- Sklearn のラッパークラスは、
SklearnRegressorとSklearnRegressorPredictを利用します。
before(5,6行目, 70-73行目)
from msi.vms.sklearn_model import SklearnClassifier
from msi.icons.vms.predict_sklearn_model import SklearnClassifierPredict
(中略)
# sklearn のモデル(パイプライン)を Alkano で利用するモデルに変換し、入力データを適用
_wrapped_model = SklearnClassifier(_pipeline)
_wrapped_model.fit(table, ycol=ycol, Xcols=Xcols)
model = SklearnClassifierPredict(_wrapped_model, include_original_input=True)
↓ after
from msi.vms.sklearn_model import SklearnRegressor
from msi.icons.vms.predict_sklearn_model import SklearnRegressorPredict
(中略)
# sklearn のモデル(パイプライン)を Alkano で利用するモデルに変換し、入力データを適用
_wrapped_model = SklearnRegressor(_pipeline)
_wrapped_model.fit(table, ycol=ycol, Xcols=Xcols)
model = SklearnRegressorPredict(_wrapped_model, include_original_input=True)
- 評価指標は回帰用の評価指標に書き替えます。
before(14行目)
score = "roc_auc" # { "type": "category", "title": "スコア", "comment": "スコアリングに利用する評価指標を選択してください。", "list": [{ "name": "Accuracy", "value": "accuracy" }, { "name": "AUC", "value": "roc_auc" }] }
↓ after
score = "r2" # { "type": "category", "title": "スコア", "comment": "スコアリングに利用する評価指標を選択してください。", "list": [{ "name": "決定係数", "value": "r2" }, { "name": "MSE", "value": "neg_mean_squared_error" }, { "name": "MAE", "value": "neg_mean_absolute_error" }] }
最終的には次のようなスクリプトになります。
import pandas as pd
from sklearn.linear_model import ElasticNet
from sklearn.model_selection import cross_val_score, KFold
from sklearn.preprocessing import OneHotEncoder
from msi.vms.sklearn_model import SklearnRegressor
from msi.icons.vms.predict_sklearn_model import SklearnRegressorPredict
from msi.common.dataframe.dataframe import pandas_to_dataframe
from sklearn.pipeline import Pipeline
# 交差検証の分割数
# MSIP_GUI_Definition_v1.0.0
n_splits = 5 # { "type": "integer", "title": "分割数", "comment": "交差検証の分割数。2以上を指定してください。" }
score = "r2" # { "type": "category", "title": "スコア", "comment": "スコアリングに利用する評価指標を選択してください。", "list": [{ "name": "決定係数", "value": "r2" }, { "name": "MSE", "value": "neg_mean_squared_error" }, { "name": "MAE", "value": "neg_mean_absolute_error" }] }
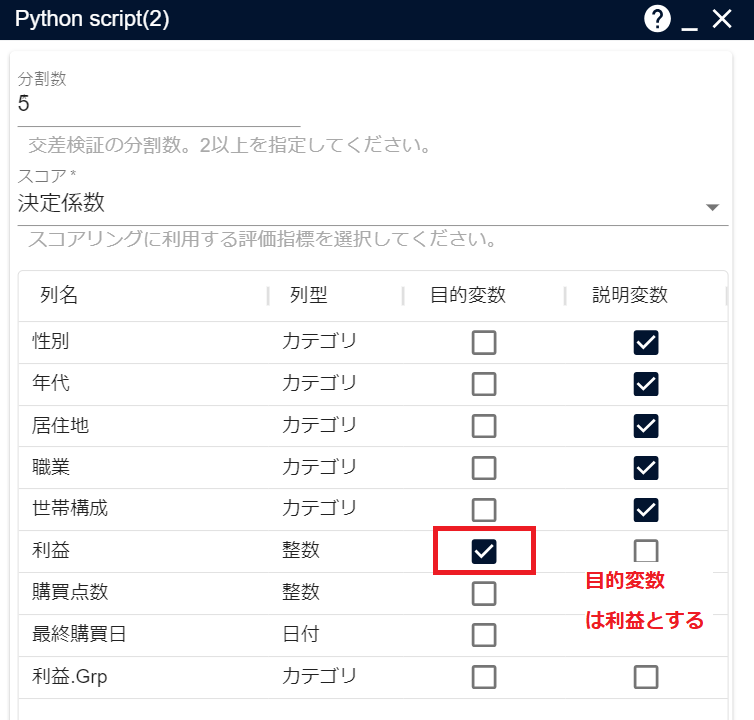
var1 = {"obj":[{"name":"利益","type":"integer"}],"exp":[{"name":"性別","type":"category"},{"name":"年代","type":"category"},{"name":"居住地","type":"category"},{"name":"職業","type":"category"},{"name":"世帯構成","type":"category"}]} # { "type": "variable", "title": "変数1", "table": "table", "columns": [{ "title": "目的変数", "field": "obj" }, { "title": "説明変数", "field": "exp" }] }
# MSIP_GUI_Definition_v1.0.0
# 説明変数の列名
Xcols = [var1["exp"][i]["name"] for i in range(len(var1["exp"]))]
# 目的変数の列名
ycol = var1["obj"][0]["name"]
# pandas のデータフレームへ変換します。
df = table.to_pandas()
parameter = parameter.to_pandas()
# Xは説明変数のデータ
X = df[Xcols]
# yは目的変数のデータ
y = df[ycol]
# 交差検証のスコアを保持するテーブル用のリスト
out_table_list = []
# 交差検証に利用したモデルを保持するためのリスト
models = []
for param_dict in parameter.to_dict(orient="records"):
# パイプラインでモデルを一纏めにします
_pipeline = Pipeline(
[
# one-hot エンコーディングを行い、カテゴリ列を数値列に直します
('encoder', OneHotEncoder()),
# Elastic Net を用いて回帰を行います
('elastic_net',ElasticNet(**param_dict))
]
)
# n_splits 分割交差検証を行う
kfold = KFold(n_splits=n_splits)
cv_score = cross_val_score(estimator=_pipeline,X=X,y=y,scoring=score,cv=kfold)
# 交差検証の結果をdictionaryに格納
out_dict = {
**param_dict,
"スコア平均":cv_score.mean(),
"スコア標準偏差":cv_score.std(),
**{
f"スコア{n+1}": cv_score[n] for n in range(len(cv_score))
}
}
# 交差検証の結果をリストに格納
out_table_list.append(out_dict)
# 交差検証の結果をログに出力
print(out_dict)
# sklearn のモデル(パイプライン)を Alkano で利用するモデルに変換し、入力データを適用
_wrapped_model = SklearnRegressor(_pipeline)
_wrapped_model.fit(table, ycol=ycol, Xcols=Xcols)
model = SklearnRegressorPredict(_wrapped_model, include_original_input=True)
# 適用後のデータをリストに格納
models.append(model)
# 交差検証の結果をデータフレームに格納
result = pandas_to_dataframe(pd.DataFrame(out_table_list))
回帰モデルなので、目的変数は数値型である必要があります。目的変数を「利益」に変更し、実行します。