

ランダムなデータを作成したい
実数型、整数型、カテゴリ型のそれぞれについて、ランダムな値を取る列を作成する方法を解説します。ダミーデータを作成するときなどに利用できます。
説明
ランダムなデータを生成するスクリプトについて解説します。具体的には、次の4つのデータの生成方法を解説します。
- 正規分布に従うランダムな実数列
- ある範囲での一様分布に従うランダムな実数列
- ある範囲の整数値をランダムにとる整数列
- 予め決めた値の中から、ランダムに値を抽出するカテゴリ列
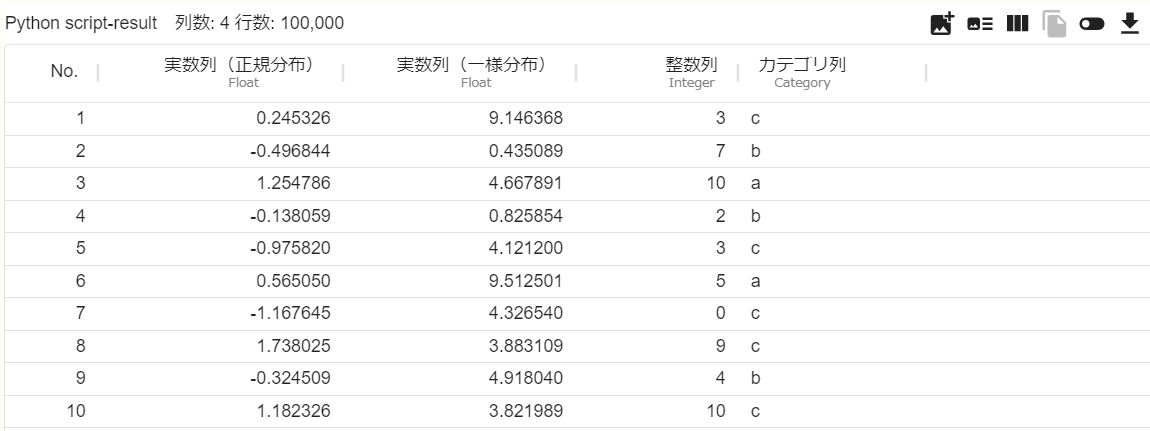
出力イメージ
使い方
- 入力とするデータはないので、シナリオエリアを右クリックし、「Pythonスクリプトを追加」をクリックし、Python script を配置します。

- 入力とするデータはないので、パラメータ設定画面を開き、「入力設定」の「-」をクリックし、入力を空にします。

スクリプトを次のように書き替えます。このスクリプトでは、
- 平均0, 標準偏差1の正規分布に従うランダムな実数列
- 0~10までの実数値が一様に分布するランダムな実数列
- 0~10までの整数値が一様に分布するランダムな整数列
- a, b, c の3つの文字がランダムに出現するカテゴリ列
の4列を作成しています。
from msi.common.dataframe import DataFrame
import random
# ランダムシード、再実行時に同様の結果が出力されるように、定数を入れています。
random.seed(42)
# データの行数
row_length = 100000
# データフレームのもととなる辞書
dataframe_dict = {
"実数列(正規分布)":[ random.normalvariate(mu=0,sigma=1) for i in range(row_length) ], # 平均0,標準偏差1の 正規分布
"実数列(一様分布)":[ random.uniform(0,10) for i in range(row_length) ], # [0,10] の区間での 一様分布
"整数列": [ random.randint(0,10) for i in range(row_length) ], # 0~10 までの整数値
"カテゴリ列": random.choices(["a","b","c"],k=row_length) # ["a","b","c"] からランダムに選択
}
result = DataFrame(dataframe_dict)
- 実行をクリックします。
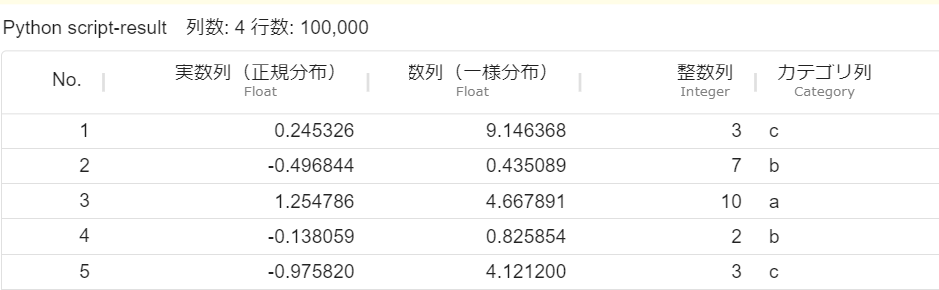
実行が終了したら可視化画面から可視化結果を確認します。
「実数列(正規分布)」列は、各値が平均0標準偏差1の正規分布に従う乱数から生成されたランダムな列です。
「実数列(一様分布)」列は、各値が0以上10以下の一様分布に従う乱数から生成されたランダムな値の列です。
「整数列」列は、整数値0~10のうちのランダムな値の列です。
「カテゴリ列」列は、"a","b","c" いずれかの値がランダムに出現する列です。
分析への応用
列の変更
Python script で出力されるデータは、スクリプト内の
# データフレームのもととなる辞書
dataframe_dict = {
"実数列(正規分布)":[ random.normalvariate(mu=0,sigma=1) for i in range(row_length) ], # 平均0,標準偏差1の 正規分布
"実数列(一様分布)":[ random.uniform(0,10) for i in range(row_length) ], # [0,10] の区間での 一様分布
"整数列": [ random.randint(0,10) for i in range(row_length) ], # 0~10 までの整数値
"カテゴリ列": random.choices(["a","b","c"],k=row_length) # ["a","b","c"] からランダムに選択
}
の部分に基づいて作成されています。
列名や列の性質を変えるにはdataframe_dictを編集しましょう。
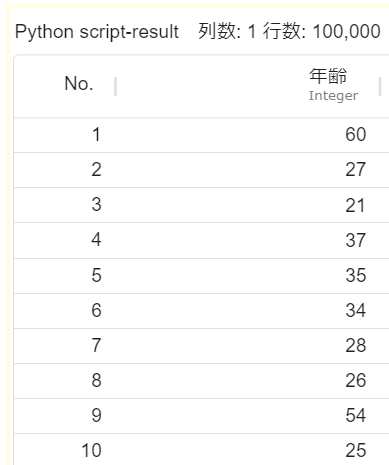
例えば、「年齢」という列名で、20から60までのランダムな整数値を埋めたい場合は次のようにdatafrane_dictを書き替えて実行します。
from msi.common.dataframe import DataFrame
import random
# ランダムシード、再実行時に同様の結果が出力されるように、定数を入れています。
random.seed(42)
# データの行数
row_length = 100000
# データフレームのもととなる辞書
# dataframe_dict の値変更
dataframe_dict = {
"年齢": [ random.randint(20,60) for i in range(row_length) ] # 20~60 までの整数値
}
result = DataFrame(dataframe_dict)
この時の実行結果は次のようになります。
行数の変更
スクリプト内のrow_lengthという変数によって決められています。
例えば、行数を10としたい場合はrow_length=10とします。
OnePoint
ランダムシード
スクリプトに、random.seed(42)という記述があります。再実行時にも、最初に実行したときと同様の乱数が得られ、結果が再現されます。random.seed(42)という記載がない場合には、実行ごとに出力データの値が変わってしまう場合があります。
実行ごとに出力データの値を変えない場合は、random.seed(42)は消さないようにしましょう。
なお、random.seed(42)の 42 はランダムシードと呼ばれる値で、乱数の元となる値です。この値を変えると、異なる乱数を生成することが出来ます。
random モジュール
乱数の生成には、Python 標準ライブラリの random というモジュールを利用しています。
今回乱数の生成のために random モジュールの次の関数を利用しています。
| 関数名 | 説明 |
|---|---|
| random.normalvariate(mu=0.0, sigma=1.0) | 正規分布です。 mu は平均で、 sigma は標準偏差です。 |
| random.uniform(a, b) | a <= b であれば a <= N <= b 、b < a であれば b <= N <= a であるようなランダムな浮動小数点数 N を返します。 |
| random.randint(a, b) | a <= N <= b であるようなランダムな整数 N を返します。 |
| random.choices(population, weights=None, *, cum_weights=None, k=1) | population から重複ありで選んだ要素からなる大きさ k のリストを返します。 |
random モジュールのその他の関数の使い方については、Python のドキュメントをご参照ください。