

scikit-learn 等のライブラリを使った分類・回帰モデルを構築・適用したい
Alkano には scikit-learn (以降は sklearn)のモデルを簡単に扱うためのラッパークラスを提供しています。 これを用いた Python Script アイコン を モデル適用アイコンや予測精度検証アイコンに接続して学習・予測をすることができます。
説明
scikit-learn では、機械学習のタスクを実行するための各コンポーネントが estimator と呼ばれる共通のインタフェースを持っています。これにより、異なるアルゴリズムや前処理手法を統一的な方法で扱えます。
estimator で定義されているメソッドには、
- fit(): モデルの学習を行うメソッド。訓練データを使ってモデルのパラメータを最適化します。
- transform() または predict(): 学習済みのモデルを用いて、新しいデータに対する変換や予測を行うメソッド。 前処理には transform() が、機械学習モデルには predict() が使用されます。
があります。 予測モデルは fit() と predict() メソッドを持っており、fit() でモデルを訓練データに適合させ、predict() で新しいデータに対する予測を行います。
Alkano のラッパークラスはこの estimator インターフェースを呼び出します。 この記事では、回帰と分類の予測モデルを呼ぶラッパークラスについて説明します。 以下の表は、回帰と分類の予測モデルを呼ぶラッパークラスについてまとめたものです。
- 「処理クラス」は、Python アイコンの実行でモデルの学習や予測を行うクラスです。
- 「他アイコンからの利用クラス」は、接続先のアイコンで入力として受け取り、学習済みモデルを用いて予測を行うクラスです。
| 対象モデル | 処理クラス | 他アイコンからの利用クラス |
|---|---|---|
| 回帰 | SklearnRegressor | SklearnRegressorPredict |
| 分類 | SklearnClassifier | SklearnClassifierPredict |
| 多目的回帰 | SklearnMultioutputRegressor | SklearnRegressorPredict |
対象モデルについて:
- 回帰モデル: 連続値を予測するモデルです。与えられた入力データに対して、対応する連続的な出力値を予測します。
- 分類モデル: カテゴリを予測するモデルです。与えられた入力データが、予め定義された複数のカテゴリのうちどれに属するかを予測します。
- 多目的回帰モデル: 複数の連続値を同時に予測するモデルです。通常の回帰モデルが1つの目的変数を予測するのに対し、多目的回帰モデルは複数の目的変数を同時に予測します。
なお、動作対象バージョンは Alkano 1.3 (MSIP 1.9) 以上です。 また sklearn のパッケージは Alkano の同梱されているバージョンとなります。 Alkano 1.5 の場合は scikit-learn 1.5.2 です。
使い方
簡単な例として、図1のようなシナリオを考えます。 この記事で解説しているシナリオは、こちらsklearnモデル使用例.msiprjからダウンロードできます。
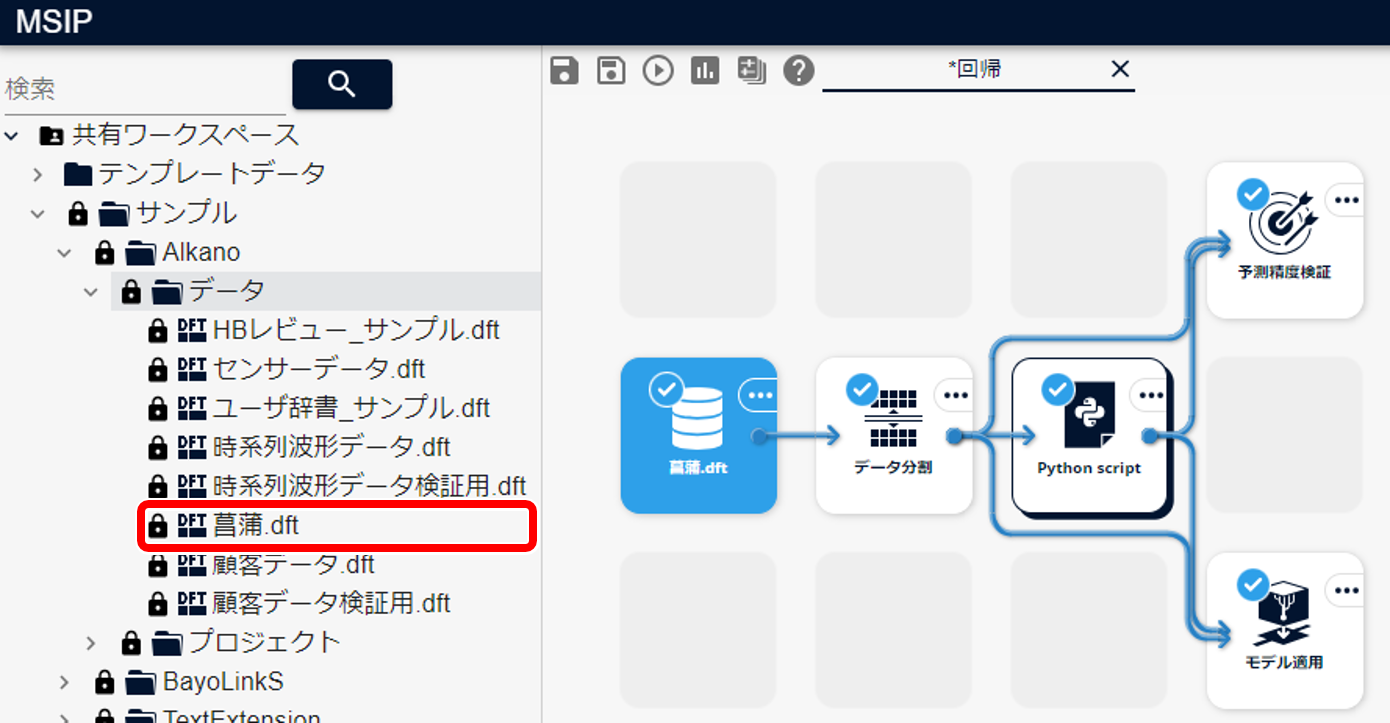
データは「共有ワークスペース/サンプル/Alkano/データ」の「菖蒲.dft」を使用します。
データ分割アイコンで、学習データと検証データに分けます。
Python Script アイコン では、sklearn のモデルを使用するスクリプトを編集します。 基本的には、ラッパークラスのコンストラクタに sklearn のモデルオブジェクトを渡してオブジェクトを生成し、 学習・予測メソッド fit、predict を呼びます。
入力は学習データ(training)です。
予測精度検証アイコン では、生成したモデルと検証データで精度検証します。 Alkano 付属の予測分析アイコンをつなげたときと同様に、confusion matrix や各種指標を得ることができます。
入力は Python Script アイコンのモデル(model)と検証データ(validation)です。
モデル適用アイコン では、生成したモデルと検証データで予測します。
入力は Python Script アイコンのモデル(model)と検証データ(validation)です。
Python スクリプトの一部が異なる以外、各モデルのシナリオは同じです。 回帰モデルのシナリオを作成後は、そのシナリオをコピーして他のモデルの学習に利用してください。 効率的に進めることができます。
回帰モデル
線形回帰 ( LinearRegression ) モデルを使用したスクリプトです。
# sklearn モデル: 回帰 from sklearn.linear_model import LinearRegression # 処理実行クラス from msi.vms.sklearn_model import SklearnRegressor # 他アイコンからの利用クラス from msi.icons.vms.predict_sklearn_model import SklearnRegressorPredict # 目的変数 ycol = "がく長" # 学習オブジェクトを生成する _sklearn_model = LinearRegression() _wrapped_model = SklearnRegressor(_sklearn_model) # 学習する _wrapped_model.fit(table, ycol=ycol) # 学習後、モデルを生成し出力する (出力設定に model を追加することが必要) model = SklearnRegressorPredict(_wrapped_model, include_original_input=True) # 学習データで予測する result = model.predict(table)
SklearnRegressor のコンストラクタに sklearn の回帰モデル LinearRegression オブジェクトを渡して学習オブジェクトを生成しています。
学習は SklearnRegressor の fit メソッドで行っています。
fit メソッドの引数には、目的変数 ycol に がく長 を指定してます。
説明変数は引数では指定してないので、目的変数以外の全列となります。
説明変数を指定する場合は、次のように引数 Xcols に列名リストを指定します。
_wrapped_model.fit(table, ycol=ycol, Xcols=["種類", "花びら長", "花びら幅"])
説明変数に 種類 というカテゴリ列を指定しています。
sklearn のモデルはカテゴリ列を扱うことはできないので、数値へ変換する処理が必要です。
ラッパークラスの fit では、説明変数中のカテゴリ列を数値列へ変換します。
数値列への変換は one-hot encoding で行っており、加えて多重共線性を避けるために、
変換された列のうち一つ (カテゴリ列にて最初に出現した値に対応する列) を取り除きます。

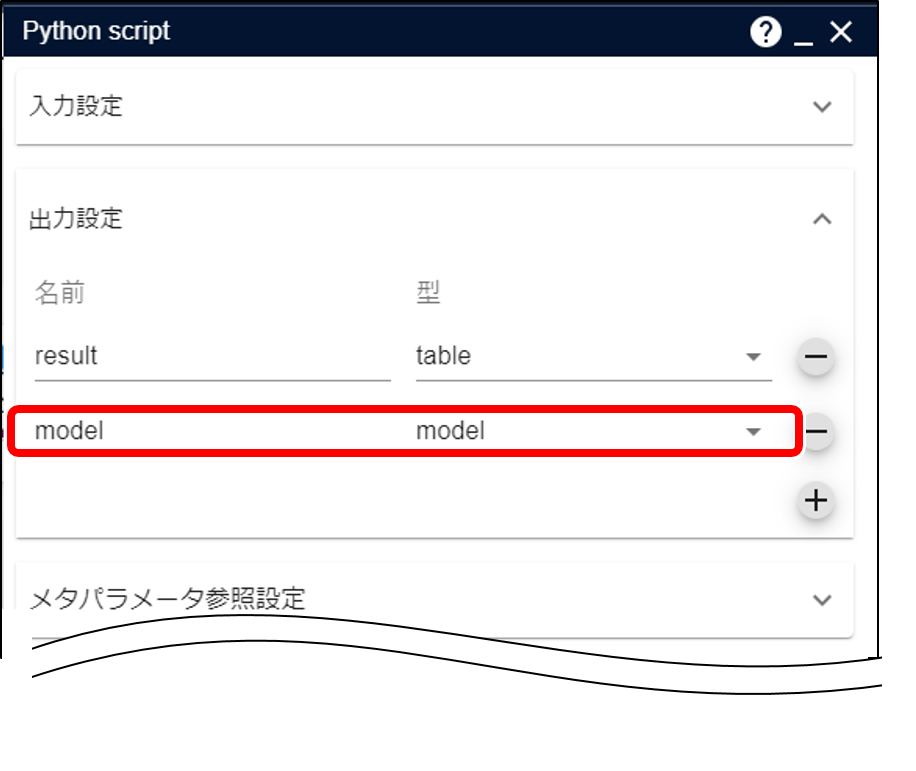
学習後、SklearnRegressorPredict のオブジェクトとして、モデルを生成しています。
include_original_input は 予測 predict 時に元データを結果に含めるかの指定です。
ここでは True にしていますので、列 predict_value の他、元データの種類、がく幅、... といった列のある結果となります。
予測精度検証アイコンやモデル適用アイコンで作成したモデルを利用するので、「出力設定」には model を追加する必要があります。
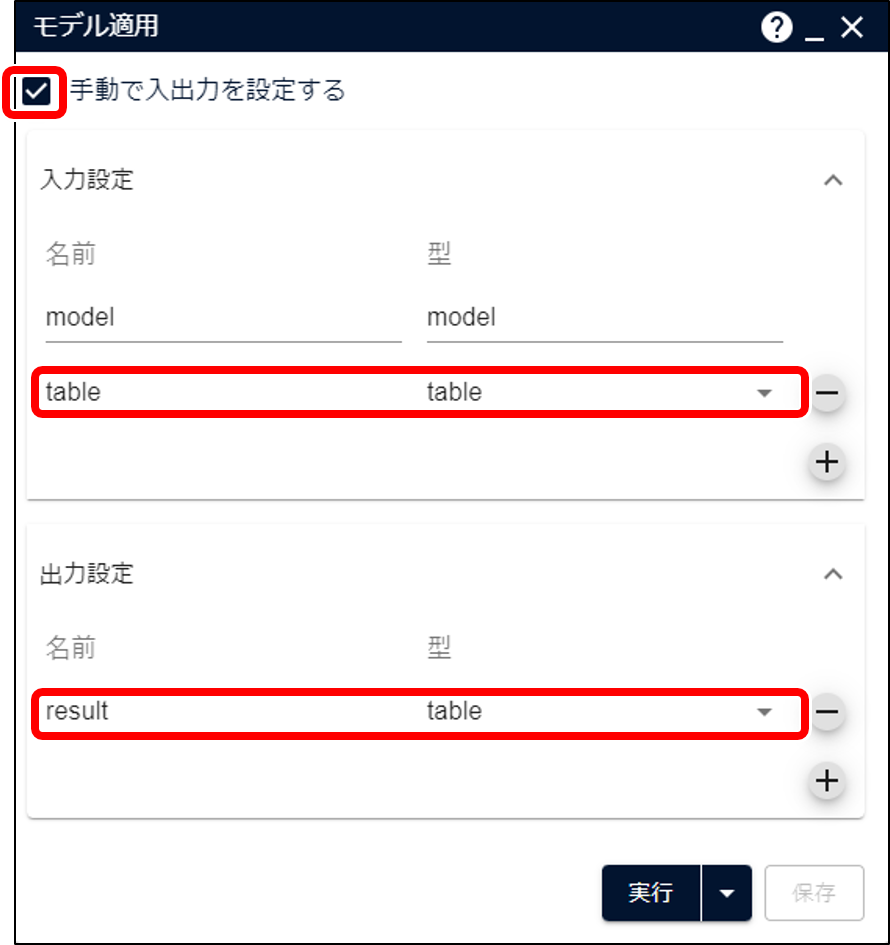
モデル適用アイコン では、Alkano 付属の予測分析アイコンをつなげた時と異なり、 「手動で入出力を設定する」を有効にして出力の定義をする必要があります。
「パラメータ設定」ダイアログの「入力設定」と「出力設定」に table 型の入力データと出力データを追加します。
予測精度検証アイコンはAlkanoの予測モデルアイコンと同様、パラメータ「正解列」を目的変数である「がく長」にします。
分類モデル
ガウス過程分類器 ( GaussianProcessClassifier ) モデルを使用したスクリプトです。 前述の回帰モデルとクラス名や変数以外は同じ処理となっています。
| 変更箇所 | 変更前 | 変更後 |
|---|---|---|
| sklearn モデル | LinearRegression | GaussianProcessClassifier |
| 処理実行クラス | SklearnRegressor | SklearnClassifier |
| 他アイコンからの利用クラス | SklearnRegressorPredict | SklearnClassifierPredict |
| 目的変数 | "がく長" | "種類" |
# sklearn モデル:分類 from sklearn.gaussian_process import GaussianProcessClassifier # 処理実行クラス from msi.vms.sklearn_model import SklearnClassifier # 他アイコンからの利用クラス from msi.icons.vms.predict_sklearn_model import SklearnClassifierPredict # 目的変数 ycol = "種類" # 学習オブジェクトを生成する _sklearn_model = GaussianProcessClassifier() _wrapped_model = SklearnClassifier(_sklearn_model) # 学習する _wrapped_model.fit(table, ycol=ycol) # 学習後、モデルを生成し出力する (出力設定に model を追加することが必要) model = SklearnClassifierPredict(_wrapped_model, include_original_input=True) # 予測する result = model.predict(table)
予測精度検証アイコンのパラメータ「正解列」を目的変数である「種類」にします。
多目的回帰モデル
PLS回帰 ( PLSRegression ) モデルを使用したスクリプトです。 前述の回帰モデルとクラス名や変数、引数名以外は同じ処理となっています。
| 変更箇所 | 変更前 | 変更後 |
|---|---|---|
| sklearn モデル | sklearn.gaussian_process.LinearRegression | sklearn.cross_decomposition.PLSRegression |
| 処理実行クラス | SklearnRegressor | SklearnMultioutputRegressor |
| 目的変数 | "がく長" | ["がく長", "がく幅"] |
| fit 引数名 | ycol | ycols |
# sklearn モデル: 多目的回帰 from sklearn.cross_decomposition import PLSRegression # 処理実行クラス from msi.vms.sklearn_model import SklearnMultioutputRegressor # 他アイコンからの利用クラス from msi.icons.vms.predict_sklearn_model import SklearnRegressorPredict # 目的変数 ycols = ["がく長", "がく幅"] # 学習オブジェクトを生成する _sklearn_model = PLSRegression() _wrapped_model = SklearnMultioutputRegressor(_sklearn_model) # 学習する _wrapped_model.fit(table, ycols=ycols) # 学習後、モデルを生成し出力する (出力設定に model を追加することが必要) model = SklearnRegressorPredict(_wrapped_model, include_original_input=True) # 予測する result = model.predict(table)
予測精度検証アイコンの検証対象は1つのみのため、パラメータ「正解列」は目的変数である「がく長」または「がく幅」のどちらかを指定します。
注意事項
モデリングモジュールでは、ラッパークラスの Python Scriptアイコンを利用できません。 モデリングモジュールに対してモデル適用を行うと予測ではなく、学習が実行されます。 予測する場合は、ラッパーモデルをモデリングモジュールからモジュール外に出し、 モデリングモジュールのモデルとラッパークラスのモデルの2つを適用する構成にします。
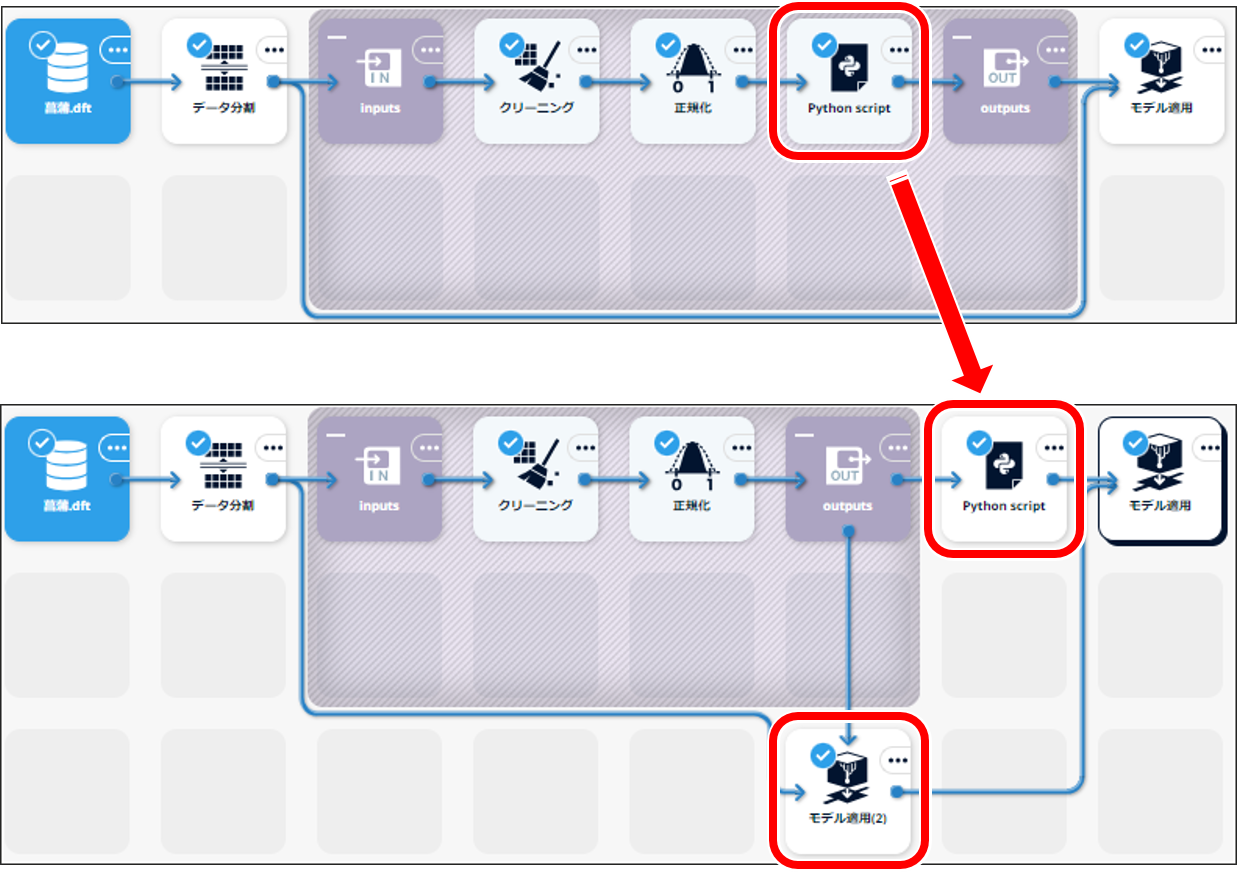
上図の例では、
- ラッパークラスの「Python script」をモデリングモジュールの外に出す
- モデリングモジュールを「モデル適用(2)」につなぎ、検証データをモデリングモジュールのモデルで処理する
- 1.の「Python Script」と 2. の「モデル適用(2)」を「モデル適用」につなぎ、2. の処理データを 1. のラッパークラスのモデルで予測する
としています。 このようにモデルを分けて各モデルを適用する構成にします。
OnePoint
Alkano の sklearn ラッパークラスは、API に互換性があれば sklearn 以外のモデルにも使用できます。
また、予測モデルの他にも fit と transform APIを有する
データ変換の汎用クラス SklearnTransformer もあります。
例えば、sklearn ではない次元削減処理クラス UMAP に
SklearnTransforer を用いたスクリプトは次です。
# sklearn モデルまたは互換モデル from umap import UMAP # ラッパークラス from msi.vms.sklearn_model import SklearnTransformer from msi.icons.vms.transform_sklearn_model import SklearnTransform # 処理対象 Xcols = ["がく長", "がく幅", "花びら長", "花びら幅"] # 前処理オブジェクトを生成する _model = UMAP() _wrapped_model = SklearnTransformer(_model) # 学習する(モデルをデータにフィッティングする) _wrapped_model.fit(table, Xcols=Xcols) # 学習後、モデルを生成し出力する model = SklearnTransform(_wrapped_model) # 変換する result = model.transform(table)
UMAP は、テクニカルサンプルプロジェクト「テキストデータの可視化・類似検索プロジェクト (version: 1.1.0)」 の「3-2. 単語の数値ベクトルの次元圧縮(t-SNE,UMAP)」や「4-2. 文章の数値ベクトルの次元圧縮(t-SNE,UMAP)」で使用されています。
関連項目
- テクニカルサンプルプロジェクト