

指定した行番号を入力テーブルから抽出したい
行番号を指定して、データを抽出します。指定した行を抜き出したり、指定した行数間のデータをすべて抜き出すことが可能です。
説明
指定した行番号を入力テーブルから抽出して、テーブル形式で出力します。
入出力イメージ
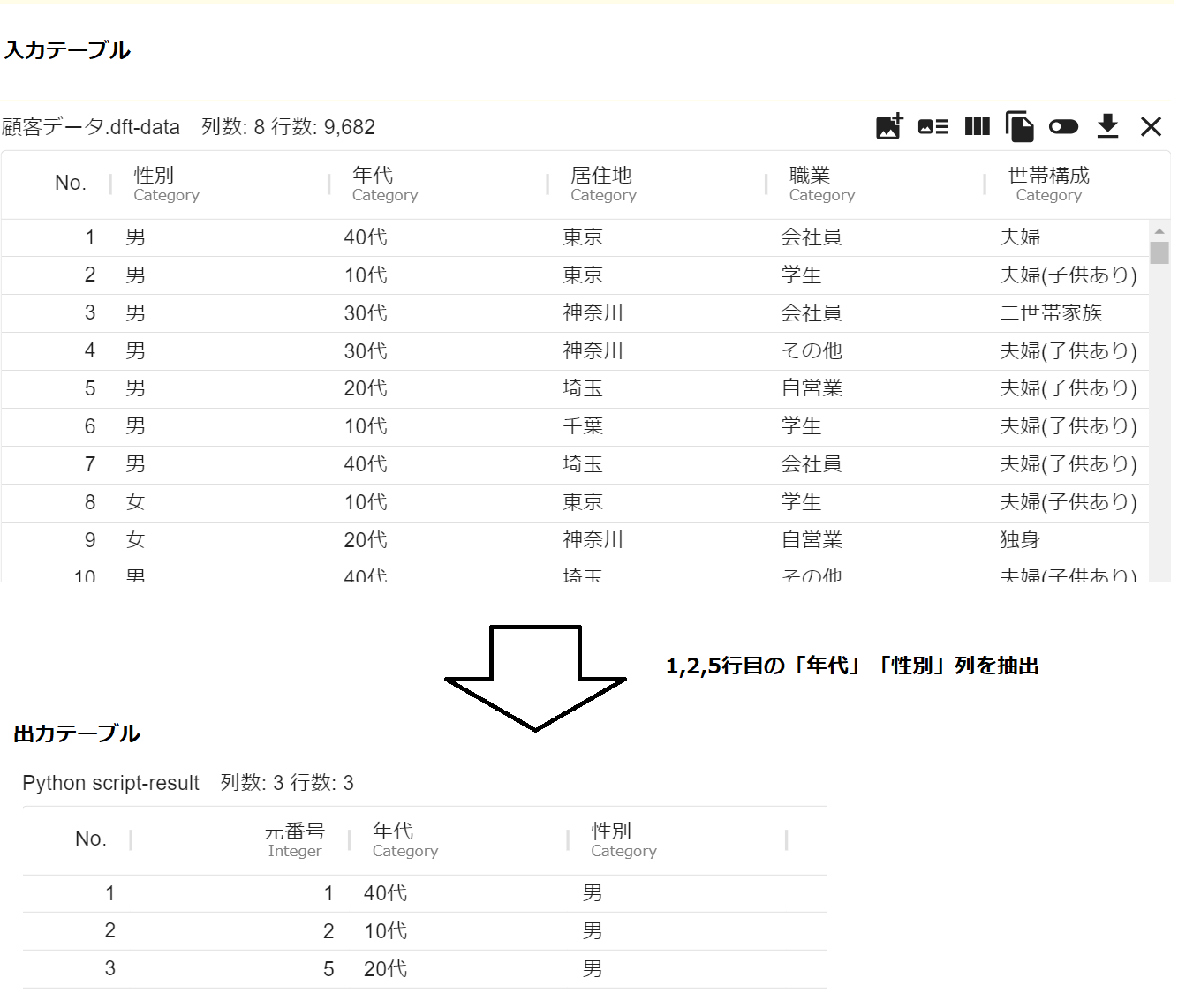
顧客データ.dft を利用し、該当の行番号、列名のデータフレームを出力する例をもとに解説を行います。
顧客データ.dft はワークスペースブラウザの
共有ワークスペース > サンプル > Alkano > データ > 顧客データ.dft
にあります。
使い方
- 顧客データ.dft をシナリオ上に配置し、「ノードを追加」から Python script ノードを追加します。
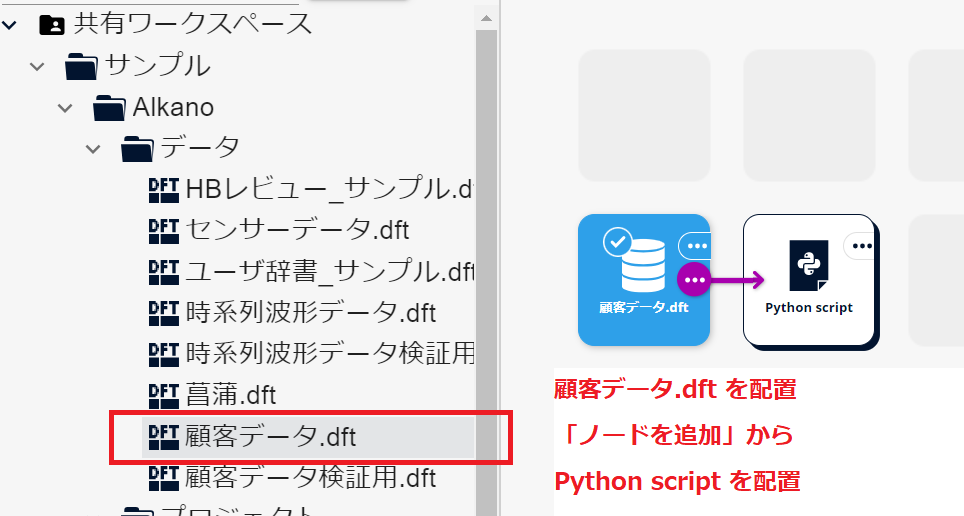
Python script ノードのパラメータ設定画面を開きます。
スクリプト内の
result=table
の部分を次の内容で上書きします。
##############################
# 設定項目
##############################
# 行番号 (可視化画面のテーブルに記載のNo.) を記載します
row_num_list = [1,2,5]
# 列名を記載します
column_list = ["年代","性別"]
##############################
# Python script で利用するtable の行番号 は No. に1を引いたものなので、row_num_list のそれぞれの値に1を引き
# row_list の値とします。
row_list = list(map(lambda x: x - 1, row_num_list))
# 元データの行番号のデータフレーム
num_dataframe = DataFrame(
{
"元番号":row_num_list
}
)
# 該当の行番号, 列名を抽出し、元番号のデータフレームと列結合します。
result = cbind(num_dataframe, table[row_list, column_list])
スクリプトの設定項目内のrow_num_list が行番号(可視化画面のテーブルに記載の「No.」列の値)のリスト、column_listが列名のリストです。
- Python script アイコン内実行ボタンを押し、可視化画面から結果を確認します。該当の行名、列名(今回は、1,2,5行目の「年代」「性別」の列)が出力できます。

分析への応用
応用1. ある1セルのみを抜き出す
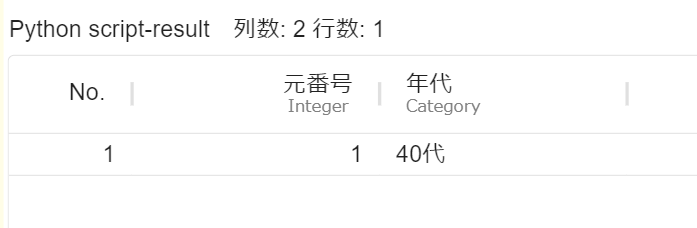
1行目の「年代」を抜き出す場合は、スクリプトの設定項目内のrow_num_listとcolumn_listを次のように編集します。
# 行番号 (可視化画面のテーブルに記載のNo.) を記載します row_num_list = [1] # 列名を記載します column_list = ["年代"]
1行目の「年代」が出力されます。
応用2. 連番で行を抜き出す
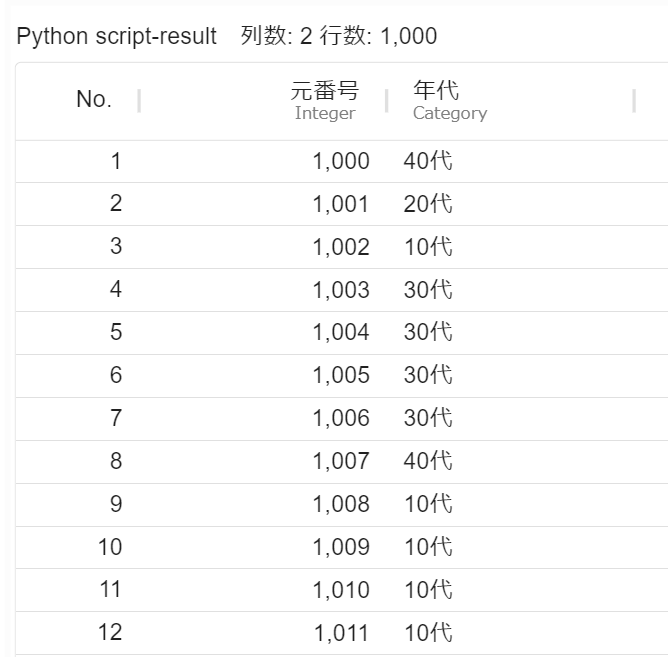
1000行目~1999行目の「年代」を抜き出す場合は、スクリプトの設定項目内のrow_num_listとcolumn_listを次のように編集します。
# 行番号 (可視化画面のテーブルに記載のNo.) を記載します row_num_list = [i for i in range(1000,2000)] # 列名を記載します column_list = ["年代"]
1000行目~1999行目の「年代」が出力されます。
OnePoint
コード内のnum_dataframeは元番号を保持するデータフレームです。
出力する際に次のようにcbind関数を利用して列結合をしています。
# 該当の行番号, 列名を抽出し、元番号のデータフレームと列結合します。 result = cbind(num_dataframe, table[row_list, column_list])
num_dataframeによって、抜き出したデータが元のデータでどの行であったかが分かります。