

複数の条件判定をもとに新たな列を作成したい
select関数を利用して、複数の条件判定を一度に行い、新たな列を作成するスクリプトです。
説明
既に存在する列から条件判定をして、新たな列を作成する汎用的な方法を解説します。「列 A の値が X または Y のときは、値が列 B と同じ値、列 A の値が Z のときは、値が 0 となる列を作成する」といったような処理の方法を解説します。
入出力イメージ
- 入力
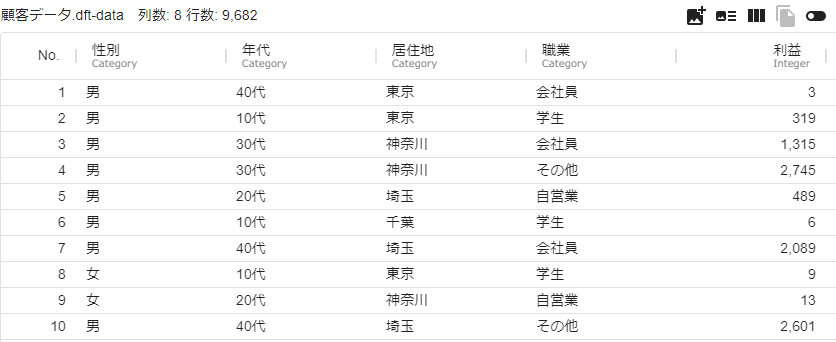
- 出力

使い方
- 計算元となるデータを用意し、「Python script」アイコンを繋げます。 (例では、顧客データ.dftを計算元のデータとしています。このデータは、共有ワークスペース>サンプル>Alkano>顧客データ.dft にあります。)
「Python script」アイコンの編集画面を開き、スクリプト部分を以下で置き換えます。 入出力設定は変更しません。
- Python script
from msi.common.dataframe import DataFrame, cbind, rbind, merge, select, is_valid, format_str
from msi.common.dataframe.params import Axis, Merge, DType, Agg
from msi.common.dataframe.special_values import Na, Error, NegativeInf, PositiveInf
### 計算の内容を記述します
## select関数で条件判定を行い、valuesに値を入れます(職業が学生なら0を、それ以外は利益列)
values = select(
(table["職業"]=="学生", 0),
default = table["利益"]
)
# valuesの列名を「結果」に設定します
values.colnames[0] = "結果"
### 複数の条件を指定します
## この例では、values2の各行には以下の値を入れます(条件判定は先に来るものが優先されます)
## ・性別が女 か 年代が10代 なら、利益を負にした値
## ・居住地が東京か神奈川 なら、利益を2倍した値
## ・購買点数が10件より多ければ、利益の値
## ・上記どれにも当てはまらなければ0
values2 = select(
((table["性別"]=="女") | (table["年代"]=="10代"), -1 * table["利益"]),
(table["居住地"].contains(values=["東京","神奈川"]), 2 * table["利益"]),
(table["購買点数"] > 10, table["利益"]),
default = 0
)
# values2の列名を「結果2」に設定します
values2.colnames[0] = "結果2"
# 元データに結合します
result = cbind(table,values,values2)
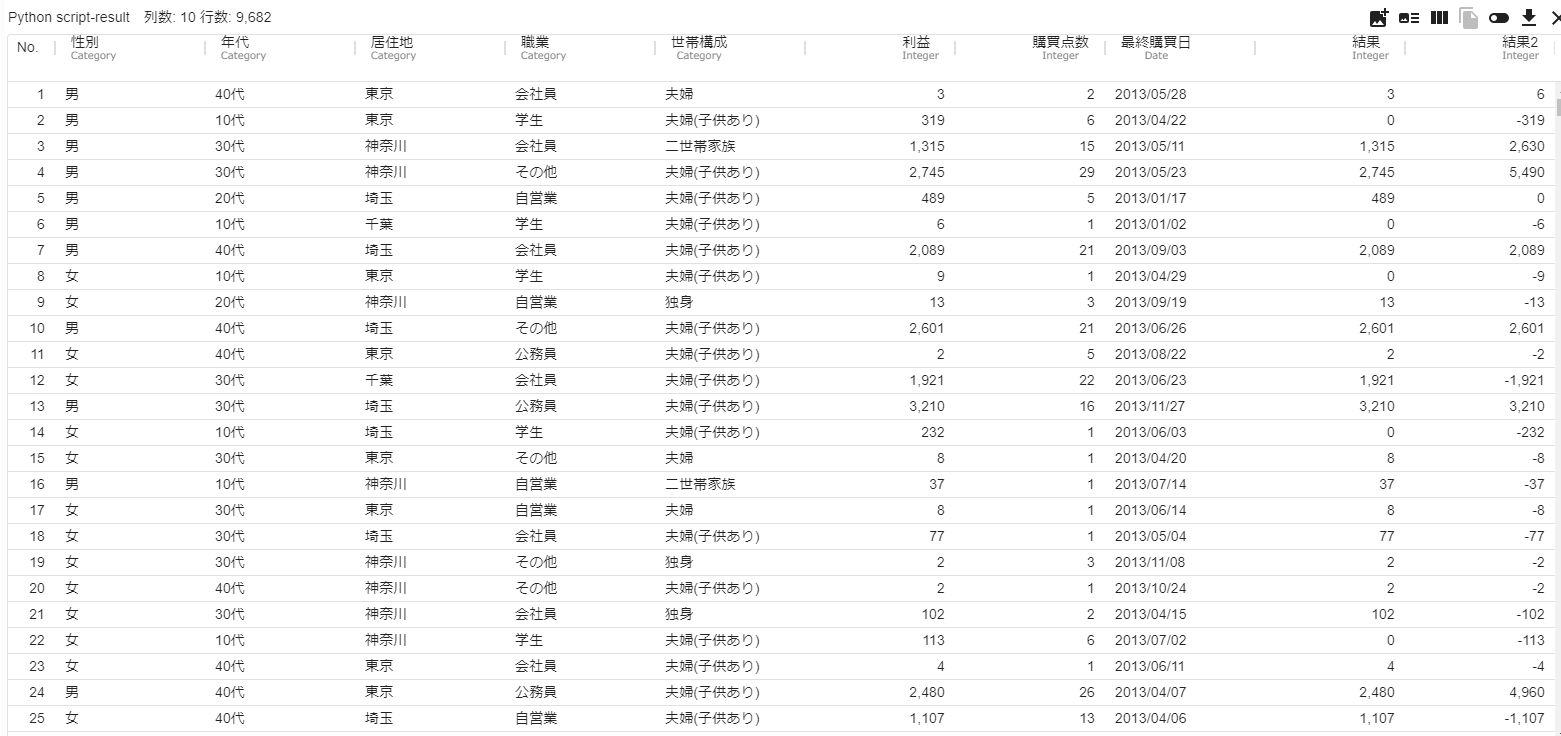
- 「Python script」アイコンを実行します。終了後、可視化画面で結果を確認すると、条件判定で計算された結果が元データに結合されています。例えば「結果」列では対応する行の「職業」列が"学生"の場合、値が0になっており、それ以外の場合には「利益」列の値が入っていることが分かります。
分析への応用
「センサーAの値が基準値以上ならセンサーAの値を、センサーAの値が基準値未満 かつ センサーBの値が基準値以上ならセンサーBの値を、センサーAの値が基準値未満 かつ センサーBの値が基準値未満のなら測定した値に意味がないものとしてNAを入れる」など、複雑な条件判定でデータの前処理を行う
OnePoint
- select関数では、与えた条件と値の組を先頭から順に評価して、最初に True となった条件に対応する値が結果になります。ただし、全ての条件が False の場合は引数 default の値が返ります。(defaultを指定しなかった場合は
Naが返ります。- 例えば、「結果2」列では3つの条件が指定されていますが、1つ目の条件「性別が女か、年代が10代」に当てはまる行は、2つ目の条件「居住地が東京か神奈川である」や3つ目の条件「購買点数が10より大きい」に当てはまっていても、「利益」列の-1倍が入っています。