

データをずらした列を追加したい
データを指定した行数分ずらして、新しく列を追加する方法を解説します。
なお、本ガイドで説明のために用いたシナリオは こちらです。 このシナリオは、テクニカルサンプルプロジェクト 時系列データ予測分析 のプロジェクトファイルを、説明のために簡略化および加工したものです。
説明
時系列データでは、未来のデータ点を予測するために、 ある時点での説明変数と、未来の目的変数を紐づける必要があります。
例えば、「1 期先のデータを予測したい」ような状況で、 1 行ごと 1 期分の情報がまとまったようなデータを持っている場合を考えます。
この際、予測したい行を 1 つ分シフトさせて新たに列を追加することで、 行に対して「その行から見た来期の値」を付与することが出来ます。
このように、シフト列を追加して目的変数を用意することで、 時系列データの予測モデルを構築しやすくなります。
入出力イメージ
- 入力
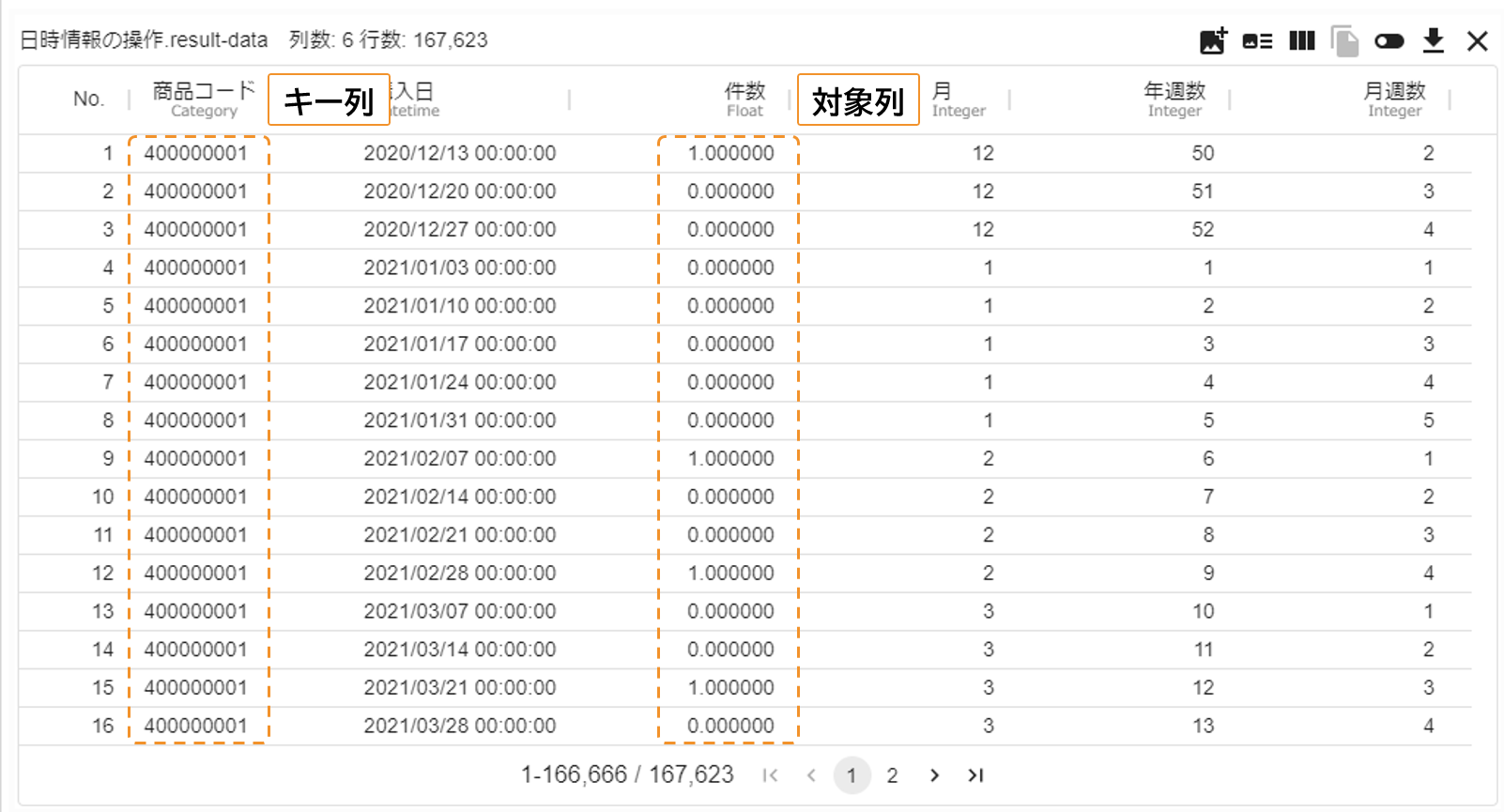
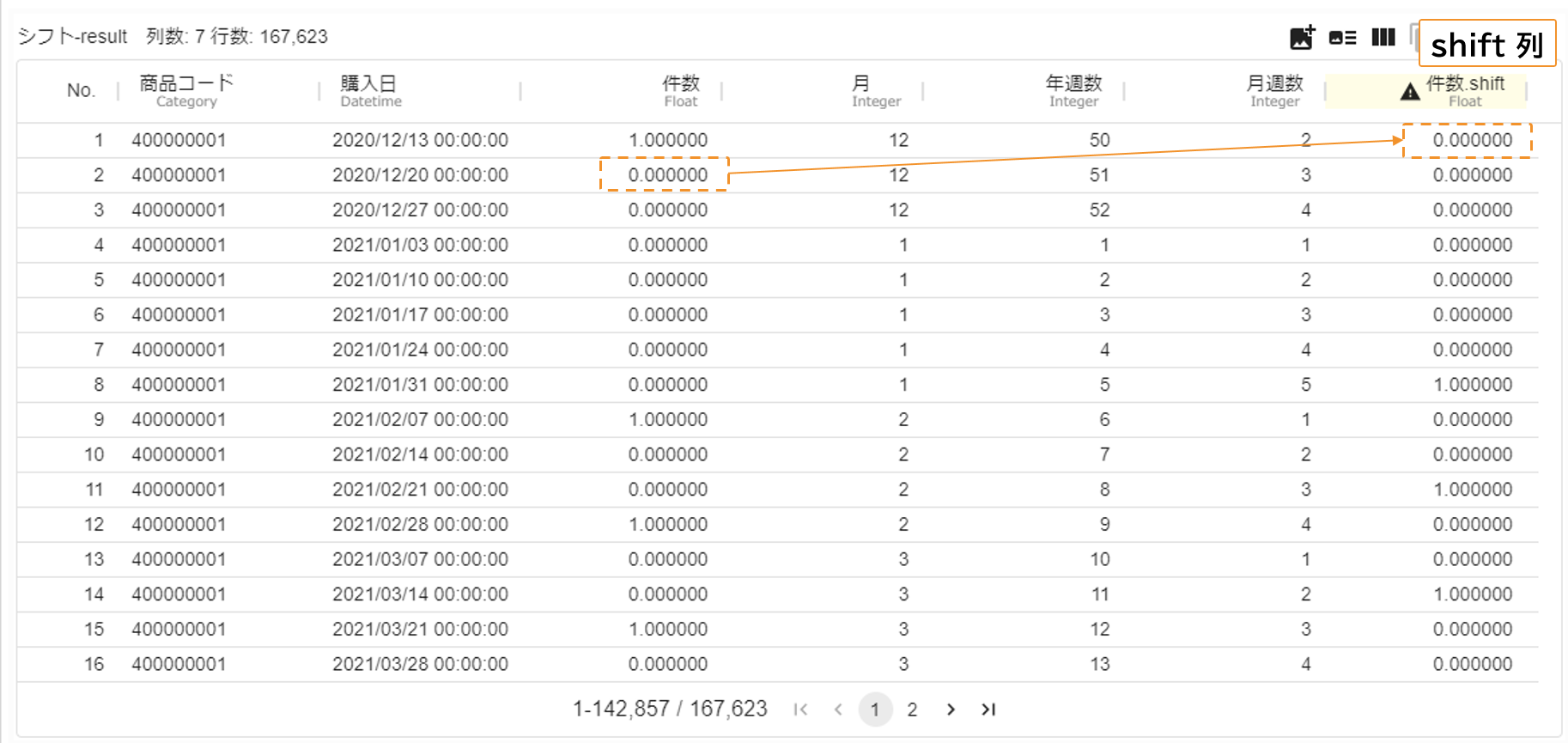
- 出力
使い方
計算元となるデータを用意し、「Python script」アイコンを繋げます。
「Python script」アイコンの編集画面を開き、スクリプト部分を以下で置き換えます。入出力設定は変更しません。
- Python script
import pandas as pd
from msi.common.dataframe import cbind, pandas_to_dataframe
"""パラメータ設定
- params の key_cols, shift_cols の配列の値
- num_shift の値
を指定してください。
"""
# 列の設定
params: dict[str, list[str]] = {
# キー列。不要な場合は空の配列にしてください。
"key_cols": ["商品コード"],
# 計算対象列。必ず 1 つ以上指定してください。
"shift_cols": ["件数"],
}
# シフト数の設定
num_shift: int = -1
"""処理内容の実装
以降は、処理の内容自体を変更したい場合にのみ修正してください。
"""
shift_cols = params["shift_cols"]
key_cols = params["key_cols"]
# 処理に必要な列のみを取り出して pandas に変換する。
__cols_to_pandas = shift_cols + key_cols
df: pd.DataFrame = table[__cols_to_pandas].to_pandas()
# shift 処理を行う。
shift_df: pd.DataFrame
if len(key_cols) == 0:
# key_cols の指定がない場合は入力データをそのまま shift する。
shift_df = df[shift_cols].shift(num_shift)
else:
# key_cols に指定がある場合は入力データをグルーピングしてから shift する。
shift_df = df.groupby(key_cols)[shift_cols].shift(num_shift)
# 列名の末尾に ".shift" を付与する。
shift_df = shift_df.add_suffix(".shift")
# pandas Dataframe を MSI Dataframe に戻し、入力データと結合して出力する。
result = cbind(table, pandas_to_dataframe(shift_df))
お手元のデータに合わせて、スクリプト冒頭のパラメータ設定を編集してください。上の例ではシフト数
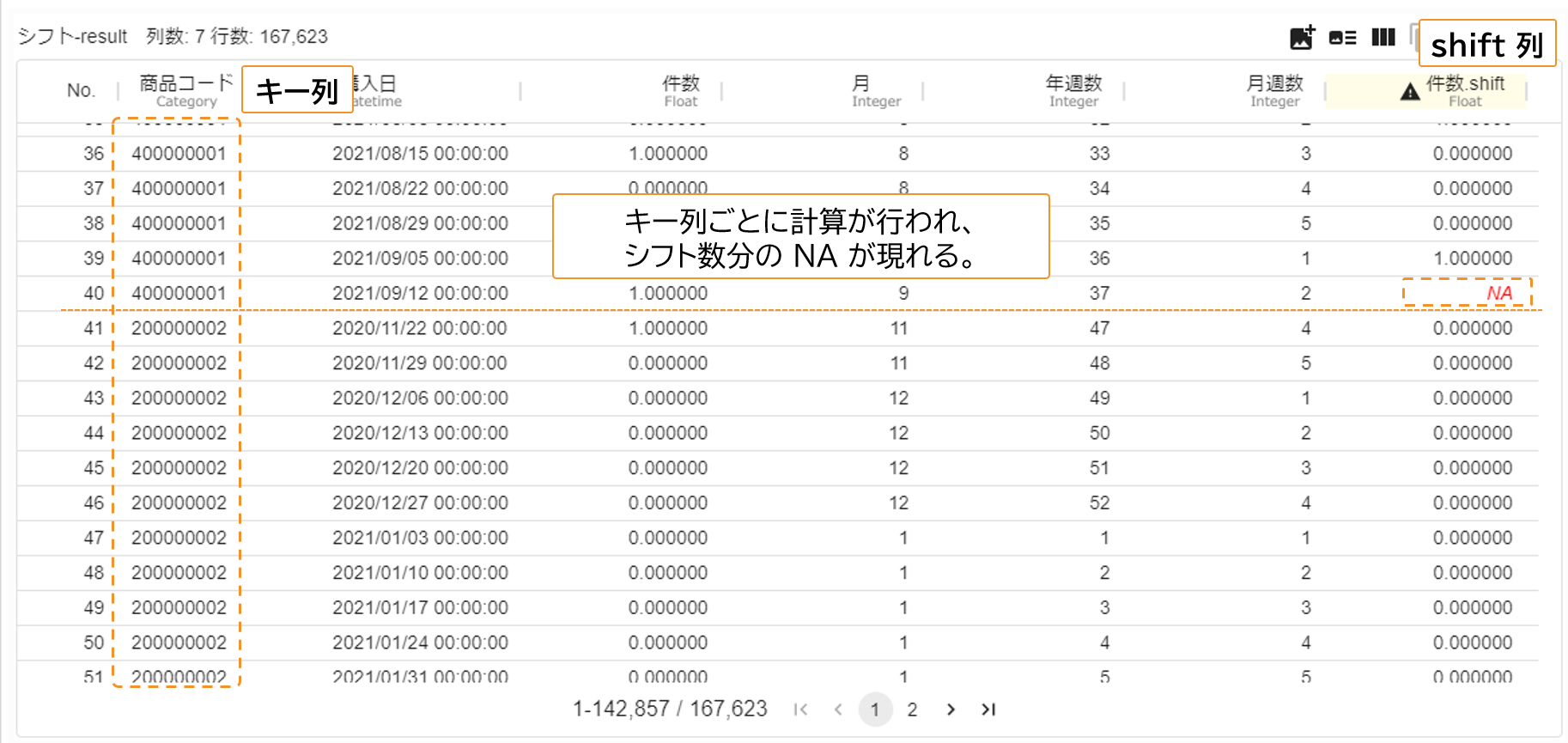
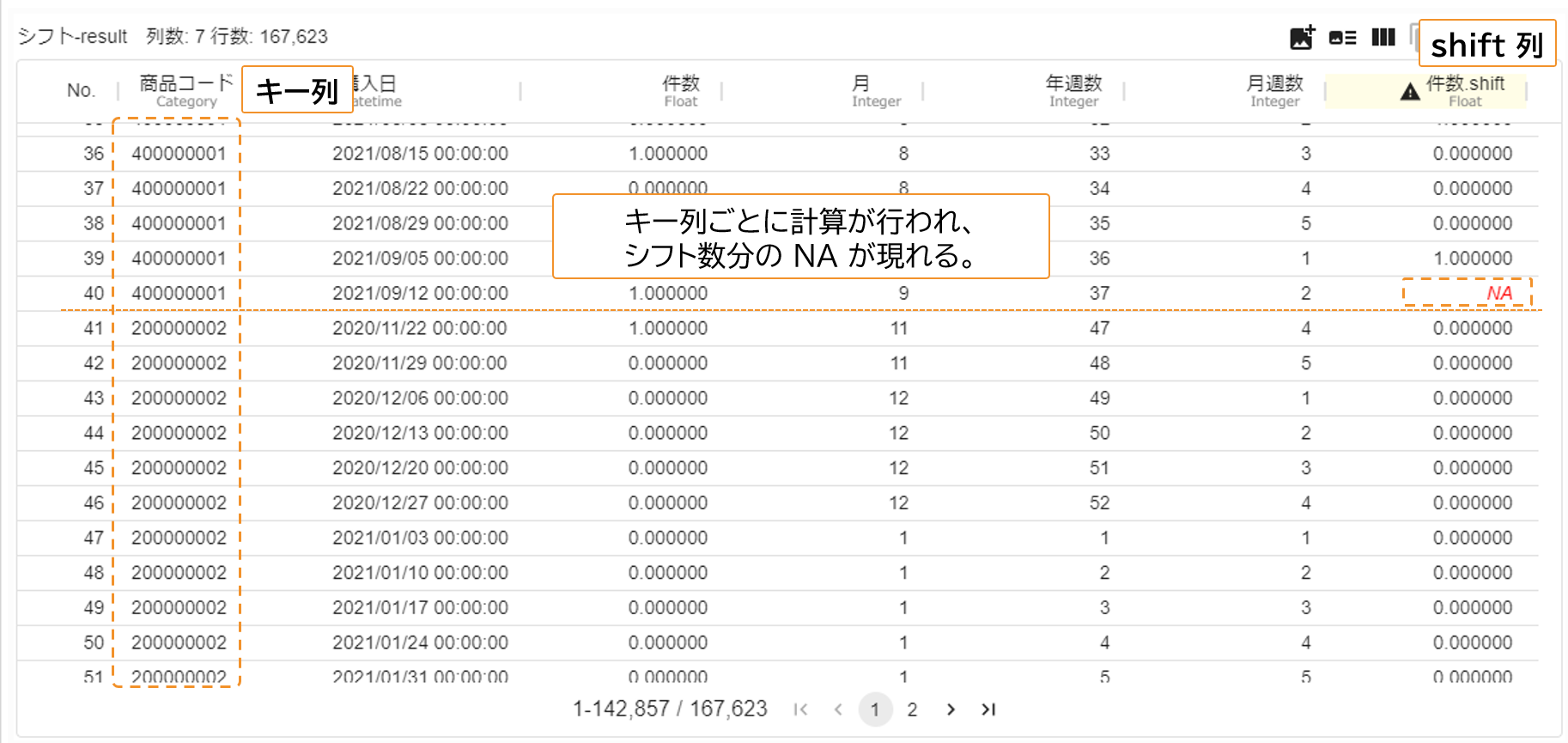
num_shiftを -1 としているため、「その行から見て一週間後の件数」の列を新しく追加することになります。「Python script」アイコンを実行します。終了後、可視化画面で結果を確認すると、キー列の値ごとに 1 行分だけデータをずらした列が追加されていることが分かります。計算の定義から、shift 列には、キー列ごとにシフト数分の NA が現れます。
OnePoint
groupby 関数を用いることで、キー列の値ごとの塊を作り、塊ごとに計算を行うことができます。