

欠損値の処理をしたい
可視化画面でNAなどの値で赤文字で表示される欠損値を処理する方法を説明します。また、欠損処理をしないと動作しないアイコンの一覧を記載しています。
説明
MSIP にインポートしたデータに欠損がある場合、欠損値は NA という特別な値として扱われます。可視化画面では赤字で NA と表され、欠損が存在する列は列名の部分に警告マークが表示されます。
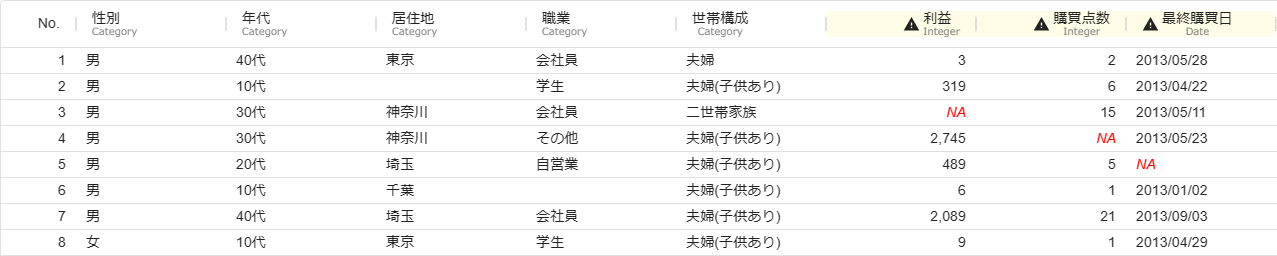
欠損が存在するデータに対して、クリーニングアイコンを用いて、以下の A, B を行って欠損が存在しないデータにする手続きを解説します。
A. 欠損値が存在する行を除外したい
B. 欠損値を別の値で置き換えたい
使い方
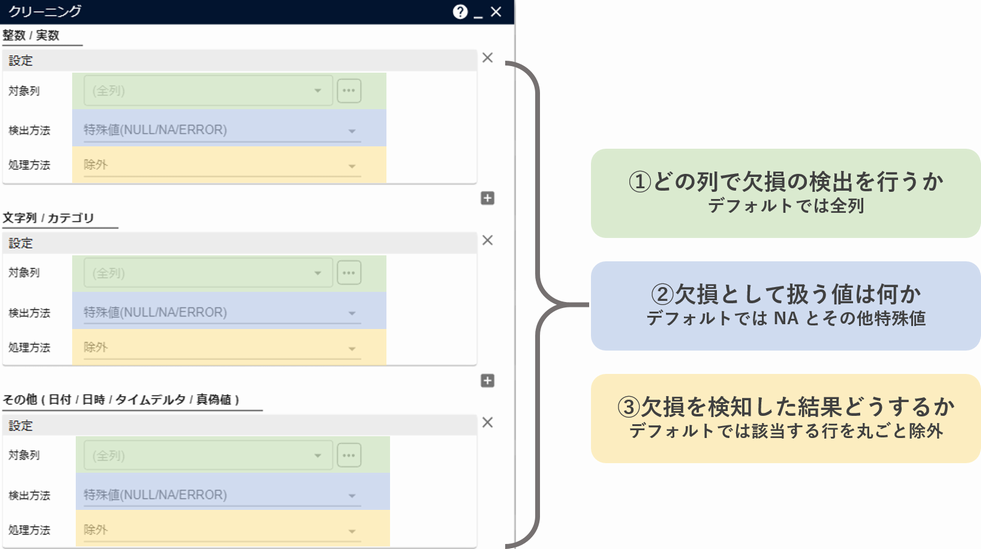
クリーニングアイコンでは、以下の3つの設定を行います。
- どの列に対して欠損を検知するか : ① 対象列
- 欠損として扱う値は何か : ② 検出方法
- 欠損を検知した結果どうするか : ③ 処理方法
この設定は、列の型に応じた数値列(整数・実数)、カテゴリ・文字列、その他(日時列等)の3種類が存在します。それぞれ、クリーニングアイコンのパラメータ画面における、上記①~③の設定箇所を示します。
A. 欠損値が存在する行を除外したい
- データにクリーニングアイコンを接続します。
- デフォルトの設定では、③ 処理方法が全て除外となっています。これはデータに欠損が存在する場合行ごと除外するという意味を表します。 したがって、デフォルト設定で実行するとデータ全体から欠損のある行を全て削除することができます。
- クリーニングアイコンを実行すると、次のような結果が得られます。

【A.発展】列や列のタイプ毎に個別に条件を指定したい
欠損値を検知するか否か、という指定は数値列、カテゴリ・文字列、その他の3種類のタイプ毎、および個々の列毎にきめ細かく設定することが可能です。
例として、次の動作を行う場合の方法を解説します。
- 数値列 のうち、「利益」列に欠損があるデータのみ削除したい
「その他」にあたる日付列「最終購買日」は欠損があるデータも削除したくない
- データにクリーニングアイコンを接続します。
- 「整数/実数」の対象列に「利益」を指定します。これにより、「利益」列の欠損値のみが検知されるようになります。
- 「その他( 日付 / 日時 / タイムデルタ / 真偽値)」の設定を ×ボタン で消去します。これにより、「最終購買日」列の欠損値は検知されないようになります。
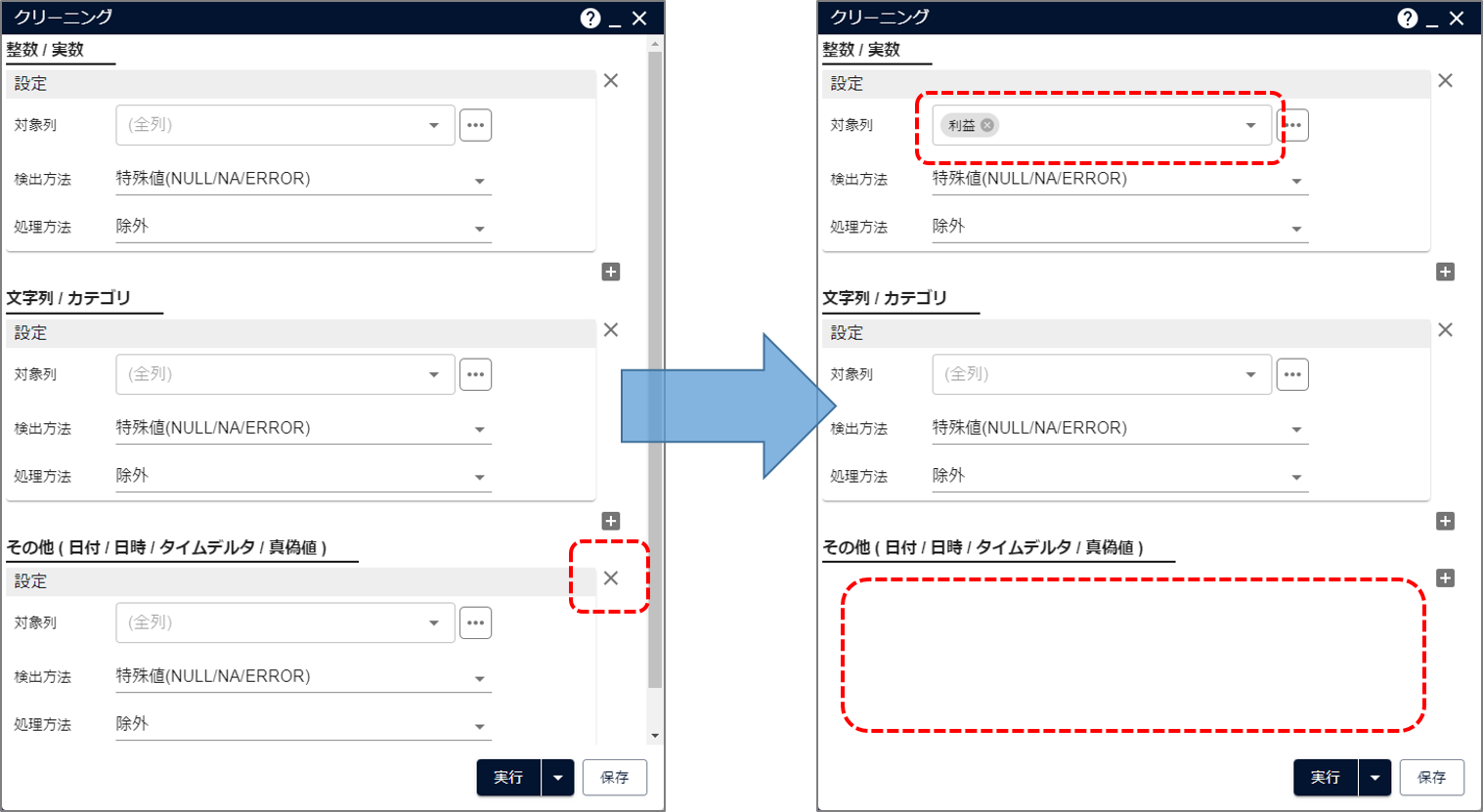
- クリーニングアイコンを実行すると、次のような結果が得られます。

B. 欠損値を別の値で置き換えたい
クリーニングアイコンでは、欠損値が存在するデータを削除するのではなく、別の値で置き換えることも可能です。
例として、次の動作を行う場合の方法を解説します。
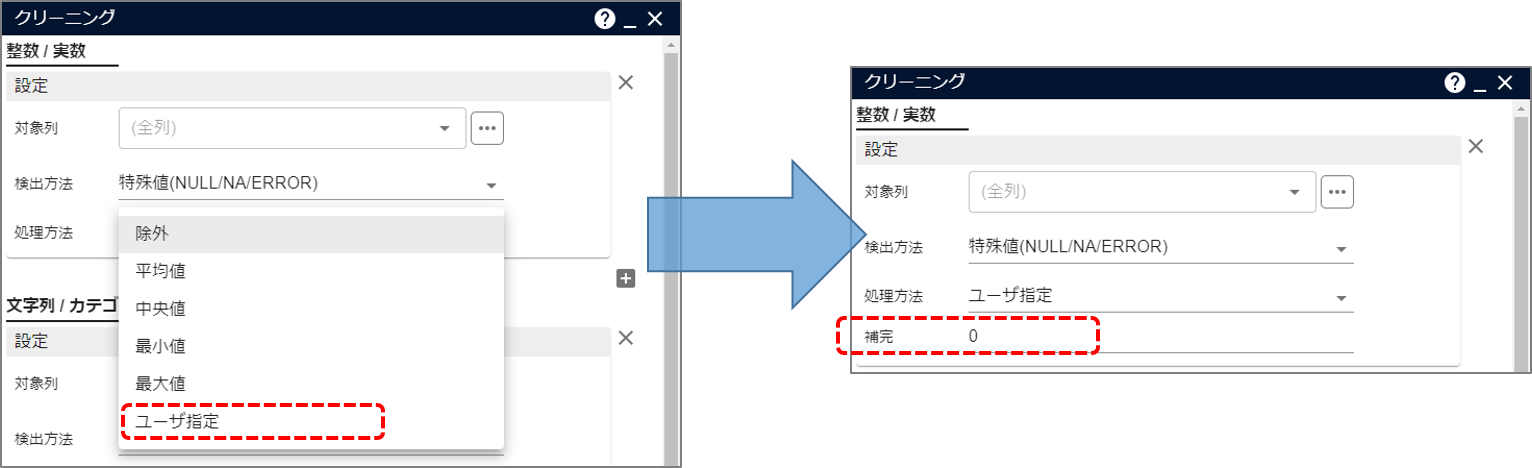
- 数値列に対して、欠損値を固定の値 0 で置き換えたい
数値列以外に欠損値があるデータは削除したい
- データにクリーニングアイコンを接続します。
- 「整数/実数」の「処理方法」を変更し、「ユーザ指定」を指定します。 数値列(整数/実数)の場合は、埋める値として平均値、中央値、等が準備されています。置き換えたい固定の値(この場合は0)が決まっている場合は、「ユーザ指定」を利用します。
- 新たに表示される項目「補完」に置き換える固定値 0 を指定します。
- クリーニングアイコンを実行すると、次のような結果が得られます。

【B. 発展】NA等の特殊値だけではなく、他の値を欠損とみなして置き換えたい
文字列やカテゴリ列においては、インポートしたデータのセルが空の場合でも、空白文字列(長さ0の文字列)とみなされて欠損値という扱いにはなりません。こういったNA以外のデータを欠損とみなして置き換えを行いたい場合の手順を解説します。
例として、次の動作を行う場合の方法を解説します。
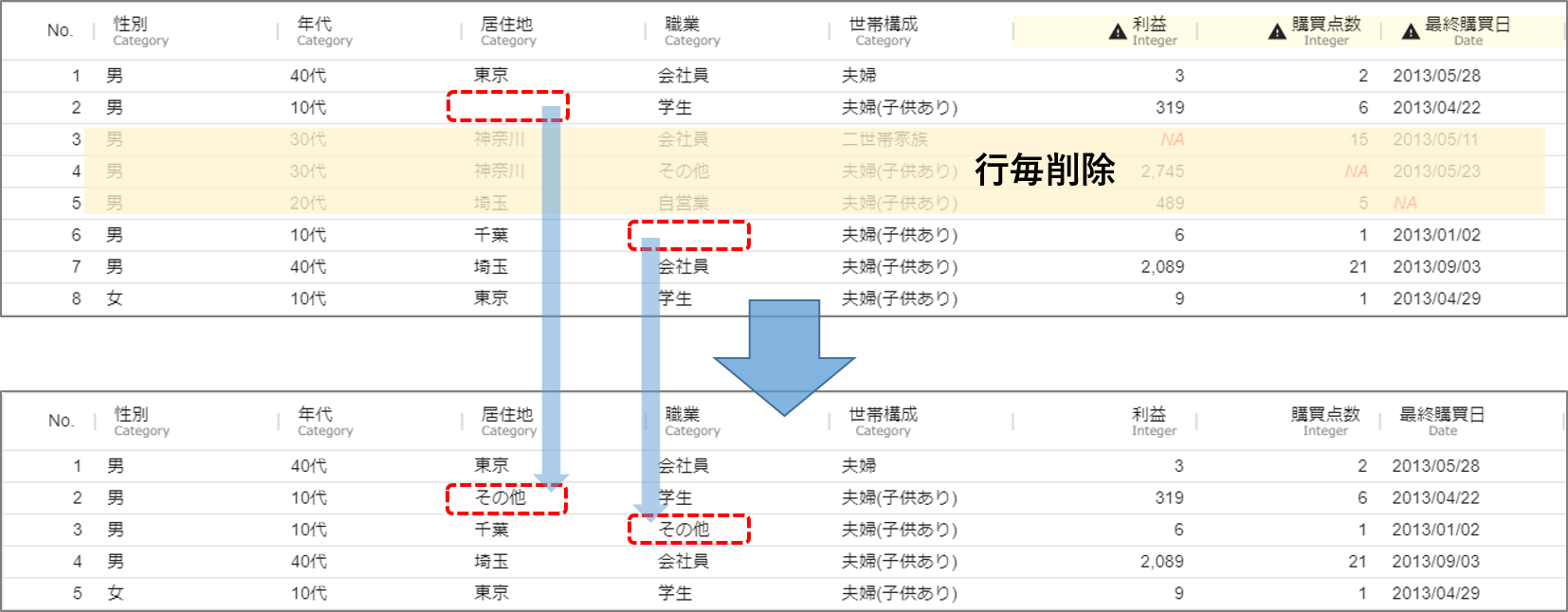
空白文字列を「その他」に置き換えたい
- データにクリーニングアイコンを接続します。
- 「検出方法」を「ユーザ指定」と設定し、「欠損基準」に欠損とみなしたい値を指定します。
空白文字列を欠損として扱いたい場合は、「欠損基準」に何も入力しないことでこの意味を表すことができます。
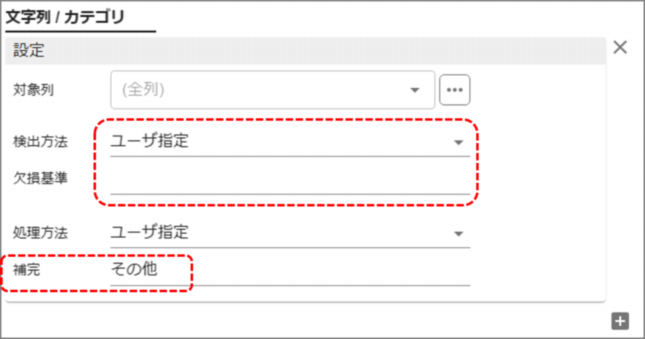
- 「処理方法」を「ユーザ指定」に変更し、新たに表示される項目「補完」に「その他」と入力します。
- クリーニングアイコンを実行すると、次のような結果が得られます。
分析への応用
Alkano の分析機能には、手法の特性上、欠損値が存在する場合に利用できないものがあります。以下のアイコンを実行する際には、本記事の手順を実行して欠損値が存在しないデータにしてから適用させてください。
- 予測分析
- 線形回帰
- ロジスティック回帰
- Elastic Net
- 代表点抽出
- クラスタリング
- ネットワーククラスタリング
- 階層型クラスタリング
- 多変量解析
- 対応分析
- 時系列分析
- 時系列特徴量作成(SFA変換)
- ディープラーニング
- ディープラーニング テーブル
- ディープラーニング 時系列
- ディープラーニング テキスト
- ディープラーニング テキスト属性
OnePoint
複数の列に対する設定を組み合わせて、「検出方法」と「処理方法」をより詳細に設定することが可能です。
例として、次の動作を行う場合の方法を解説します。
「利益」と「購買点数」の 2つの数値列がある
- 「利益」の欠損値は 0 で置き換えたい
ただし「購買点数」が欠損であるデータは除外したい
- データにクリーニングアイコンを接続します。
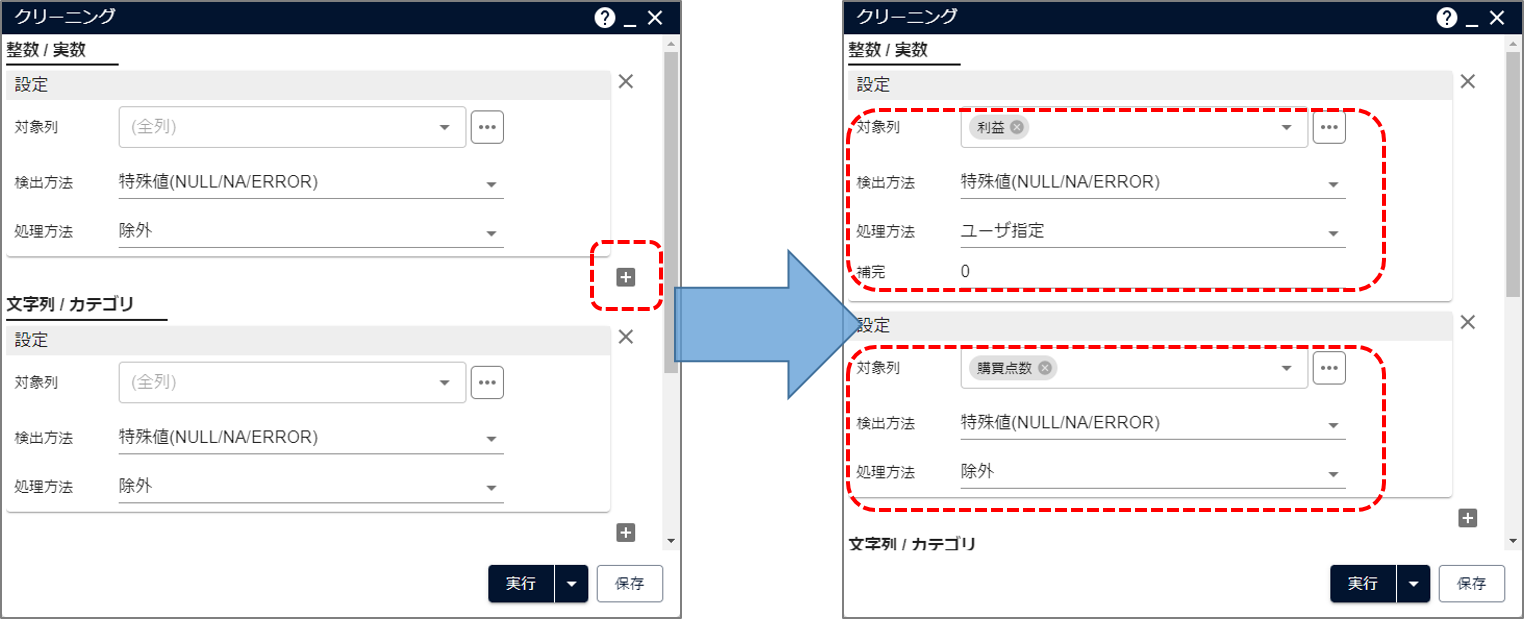
- 数値列「利益」と「購買点数」の間で異なる設定を行いたいため、「整数/実数」の + ボタンをクリックして入力項目を追加します。
- 片方の入力項目で次の設定を行います。 ・対象列 : 利益 ・処理方法 : ユーザ指定 ・補完 : 0
- もう片方の入力項目で次の設定を行います。
・対象列 : 購買点数
・処理方法 : 除外
- クリーニングアイコンを実行すると、次のような結果が得られます。

関連項目
なし