

学習用データと検証用データに分割してモデルの評価をしたい
ホールドアウト法と呼ばれる方法で決定木モデルの予測精度を検証するシナリオの作成方法を解説します。
説明
データを分析アイコンに入力して学習モデルを作成する際には、
- 学習したモデルを用いて未知のデータを正しく予測できるか(予測精度が良いか)
- 学習データに過剰に適合してしまっていないか(過学習になっていないか)
という点に注意する必要があります。
ここでは、MSIP上で学習モデルが適切に作成されているかを定量的に評価する方法を紹介します。
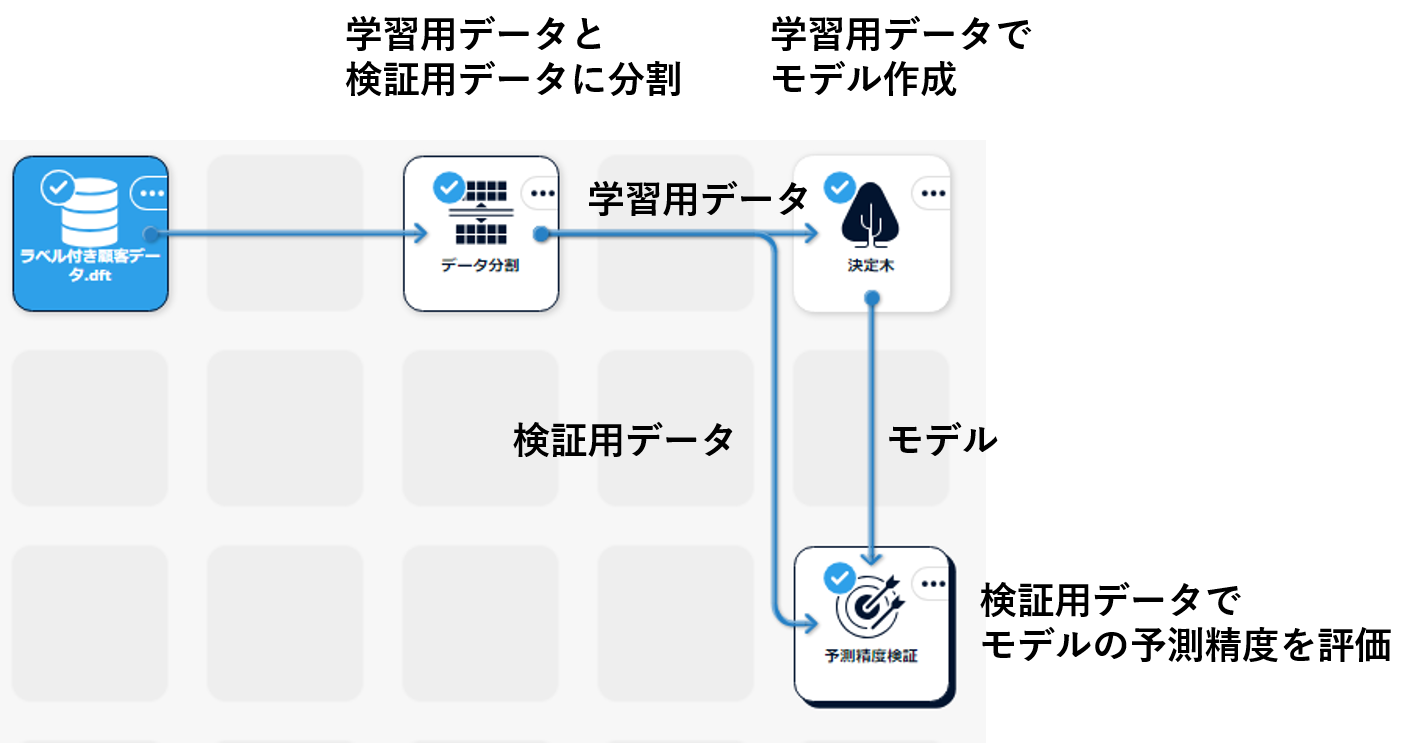
- データ分割アイコンを用いてデータを学習用データと検証用データに分割します。
- 学習用データから学習モデルを作成します。
- 検証用データと学習モデルを予測精度検証アイコンに入力して精度を評価します。
このようにデータを学習用データと検証用データに分割して学習モデルを評価する検証方法を、ホールドアウト法と呼びます。
使い方
MSIPのデータ分割アイコンを利用することで、データを学習用データと検証用データに分割することができます。
- データにデータ分割アイコンを接続します。
- パラメータ設定画面で学習用データと検証用データの割合を設定します。
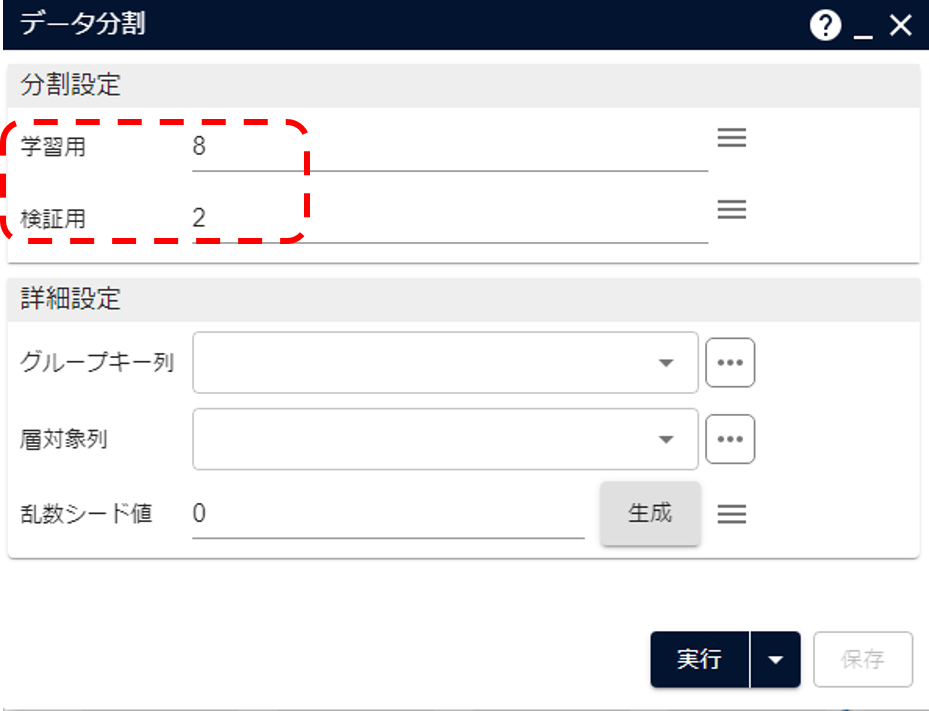
- 実行すると、入力されたデータが学習用データ(
training)と検証用データ(validation)の2つに分割されて出力されます。
この学習用データと検証用データを使用することで、ホールドアウト法による学習モデルの検証がおこなえます。
実際に、以下のようなホールドアウト法による学習モデルの検証のフローを作ってみましょう。
ここでは、学習モデルは決定木アイコンを用いるとします。
- データをデータ分割アイコンに入力し、学習用データと検証用データに分割します。
- データ分割アイコンから決定木アイコンを接続します。
- 決定木アイコンの入力設定で、データ分割アイコンの学習データが入力されているように設定します。
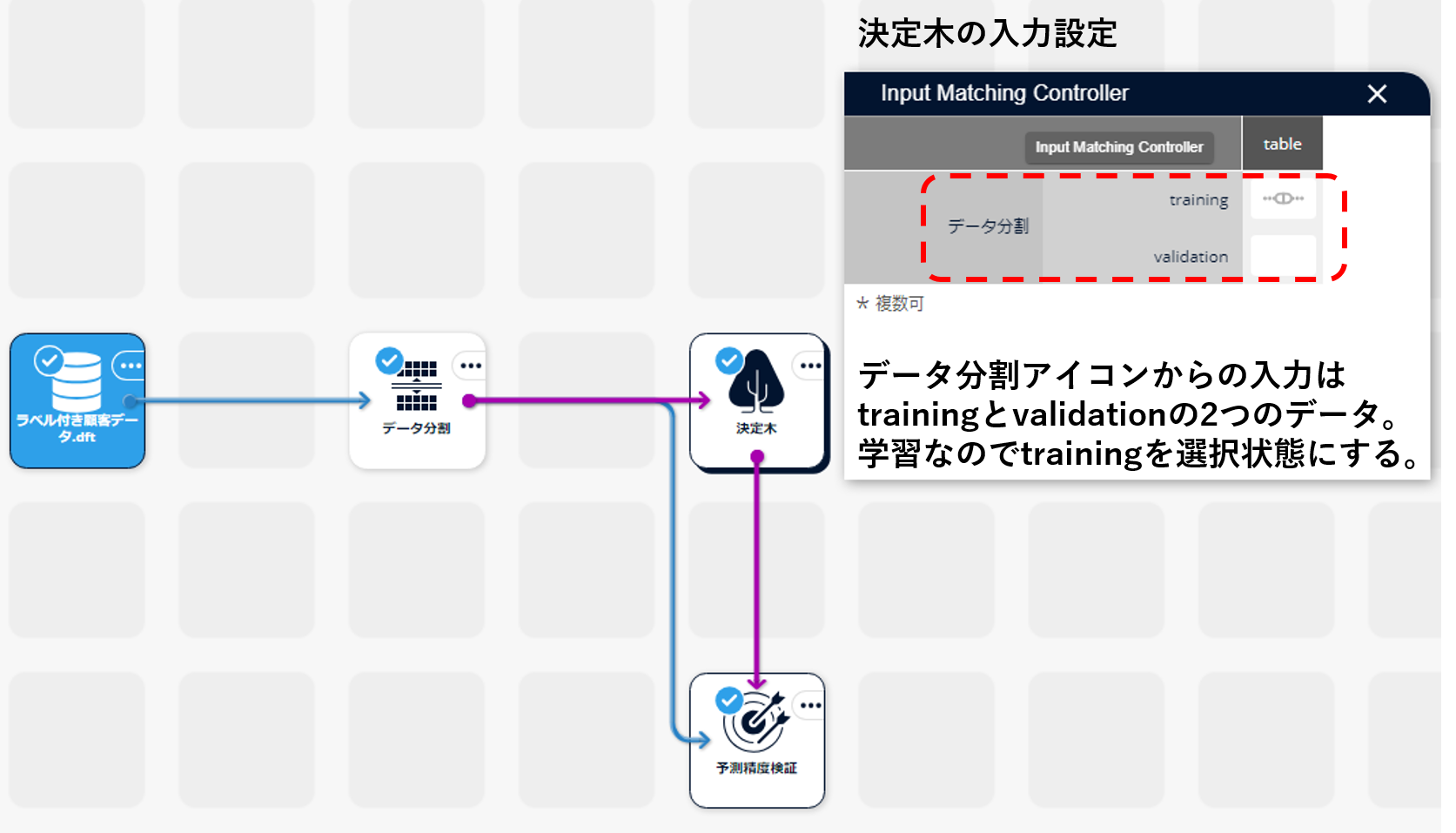
- 決定木アイコンを実行します。
- 決定木アイコンから予測精度検証アイコンを接続します。
- データ分割アイコンから予測精度検証アイコンにフローを繋ぎます。
- 予測精度検証アイコンの入力設定で、決定木アイコンのモデルとデータ分割アイコンの検証データが入力されているように設定します。
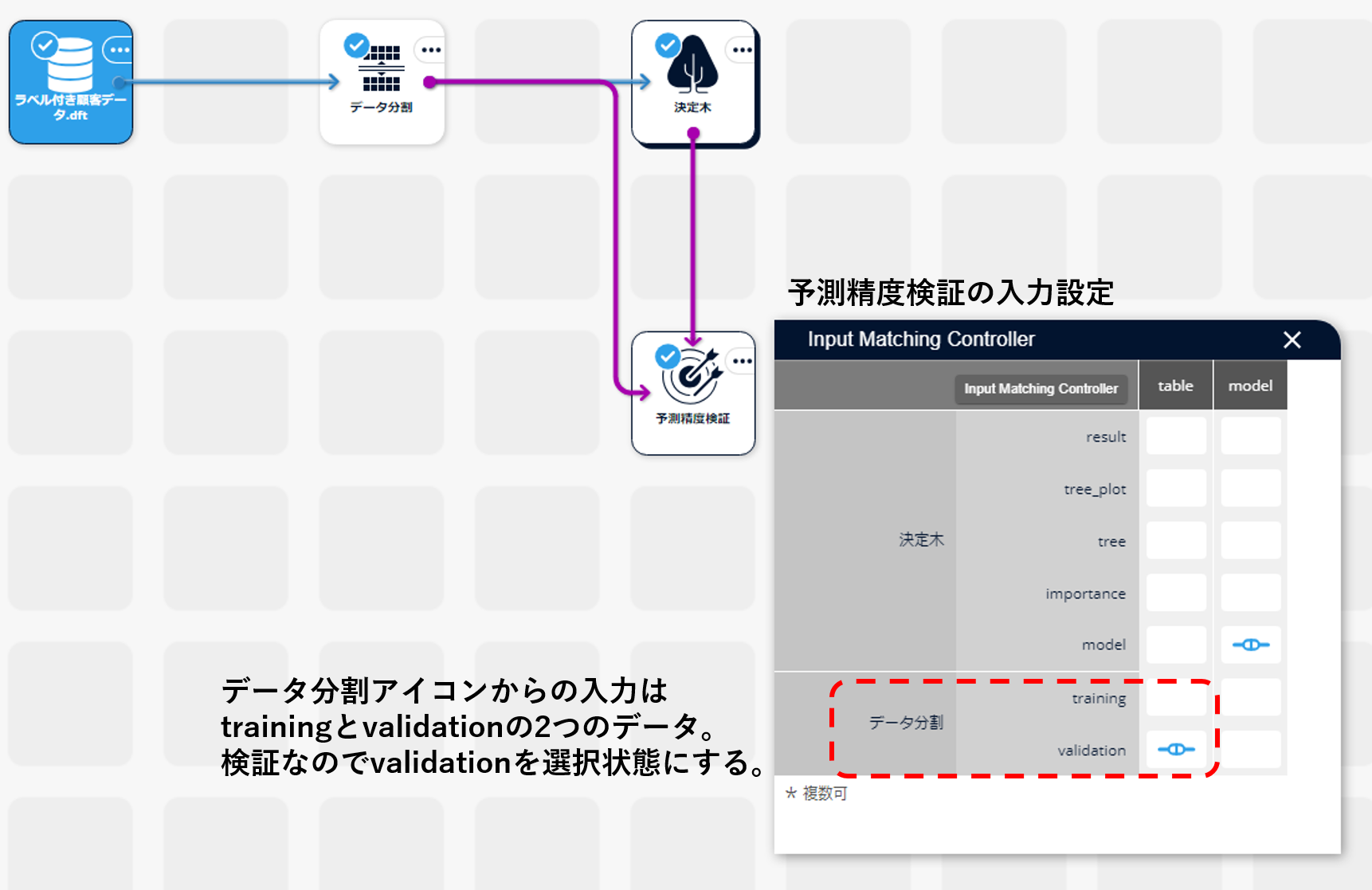
- 予測精度検証アイコンを実行すると、学習モデル検証用の各種指標値が出力されます。
ここでは、予測精度検証の出力の例として混同行列のヒートマップ(confusion matrix heatmap)を見てみましょう。
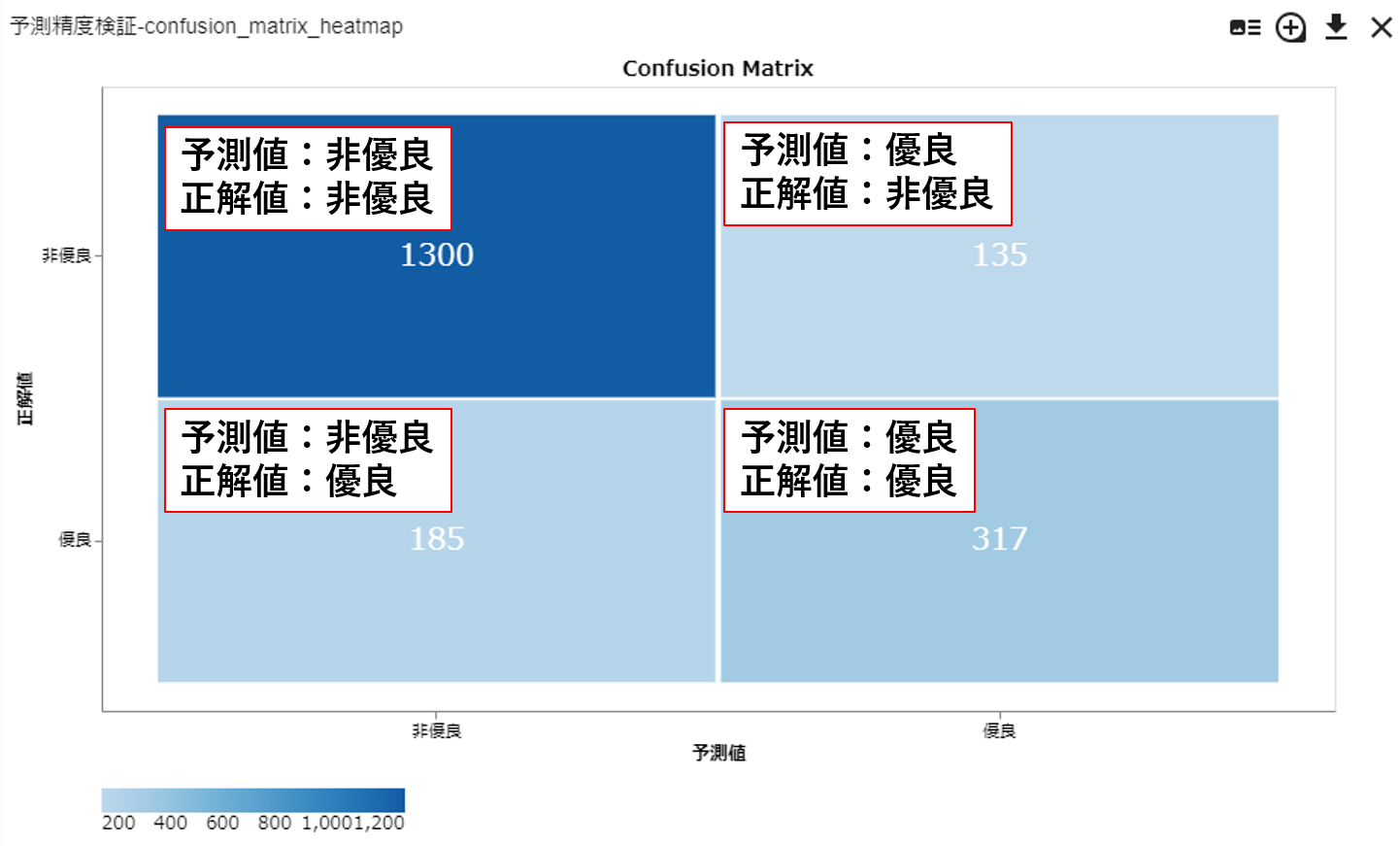
混同行列ヒートマップでは、学習モデルが予測した結果が合っていたか、間違っていたかを、マトリックス状のヒートマップの形で表現します。
この例では、検証データに対してモデルを適用した場合に、 ラベルが優良と予測されてそのラベルが実際に優良だったデータが317件、 ラベルが非優良と予測されてそのラベルが実際に非優良だったデータが1300件、 というように予測が正解だったケースが対角線上に、予測が不正解だったケースがそれ以外の場所に並びます。
これを元に、なるべく正解が多く不正解が少なくなるように、学習アイコンを変えたり、学習アイコンのパラメータを調整することになります。 また、説明変数を適切に選ぶことでも予測精度が良くなる場合があります。
OnePoint
ホールドアウト法をより精密にしたモデル評価手法に、交差検証という手法があります。
MSIPでは、交差検証を用いた最適化機能を利用することができます。
詳細については、MSIPマニュアル「3.16. 最適化機能」をご参照ください。
関連項目
MSIPマニュアル
- 3.16. 最適化機能